
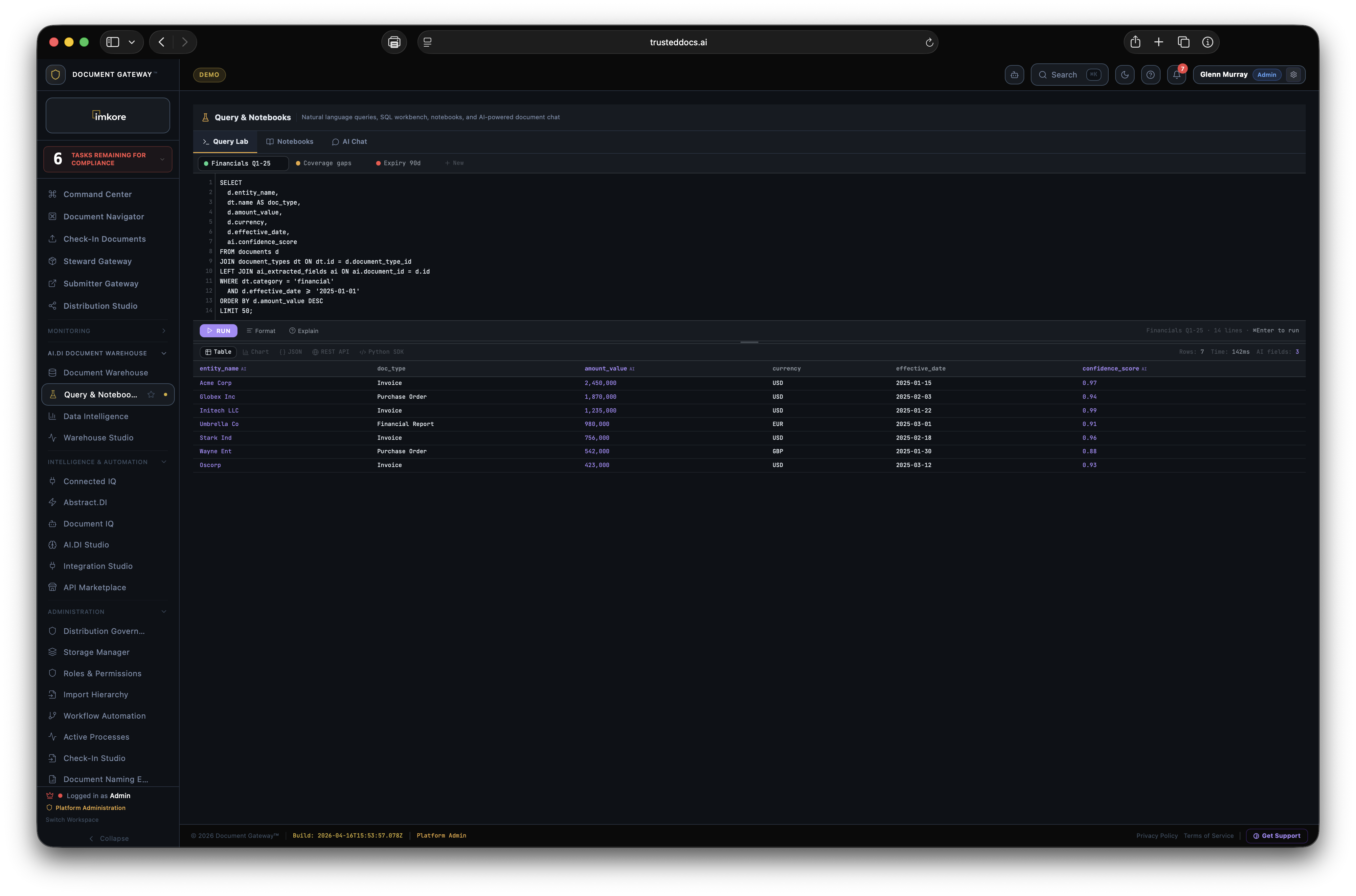
Other systems organize documents. AI.DI yields the intelligence inside them. Every field, every date, every party, every obligation, every number buried in every document becomes structured, queryable, and routable data your business can actually act on. We clean up the mess already sitting in your storage platforms. More importantly, we prevent the mess from ever forming again. The documents that matter stop being closed interpretations and start being open intelligence.
Box, SharePoint Copilot, M-Files, and Hyland all share the same starting point. A file storage system built in a different era, with AI features layered on top. Layered AI produces generic summaries. Native AI produces structured intelligence from every field of every document. The kind you can actually query, export, certify, and act on.
The AI.DI Document Warehouse cannot be retrofitted onto a file system. It is not a feature. It is the foundation. Building it requires starting over. AI.DI did. That is the entire difference.
Every other platform is a dumping ground. Anyone can upload anything, name it whatever they want, and create another folder no one else can find. Multiply that across thousands of users for ten years and you get the document chaos every organization is living with right now.
AI.DI is the opposite. It handles only the documents that matter. Every document is classified, structured, certified, controlled, and branded. Access is governed at the database. Discipline is enforced by the platform. Document culture replaces document chaos. This is what a real Document Intelligence framework looks like.
Every enterprise AI deployment runs into the same wall. The documents feeding the model are unverified, duplicated, mislabeled, and structurally inconsistent. Copilot hallucinates because the underlying SharePoint is untrustworthy. The model is not the problem. The data is.
AI.DI certifies every document before it ever reaches an AI pipeline. Sentry fingerprints make it mathematically impossible to feed a falsified document into an answer. Every response is traceable to a certified version with a confidence score. This is what trustworthy enterprise AI looks like.
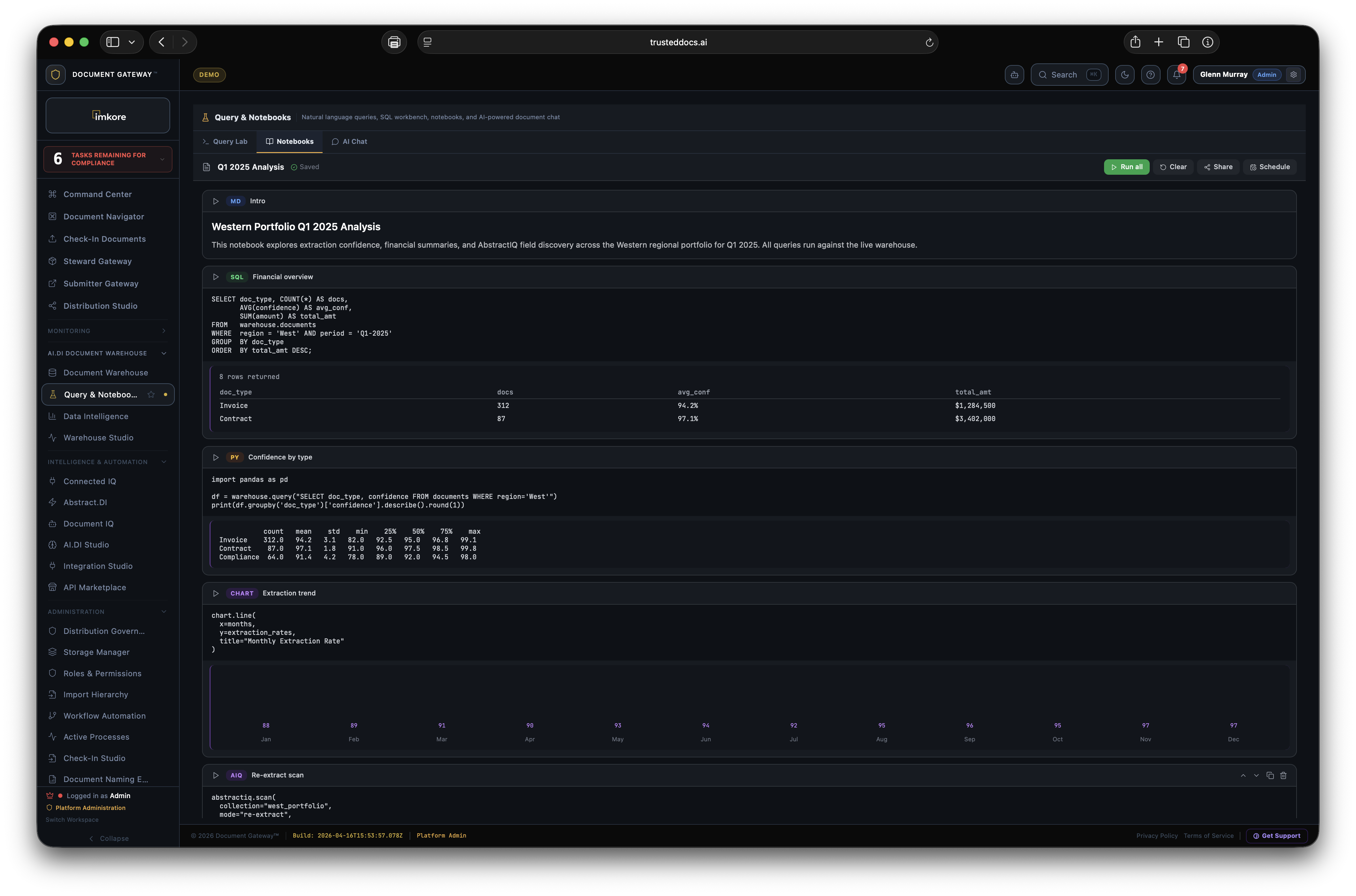
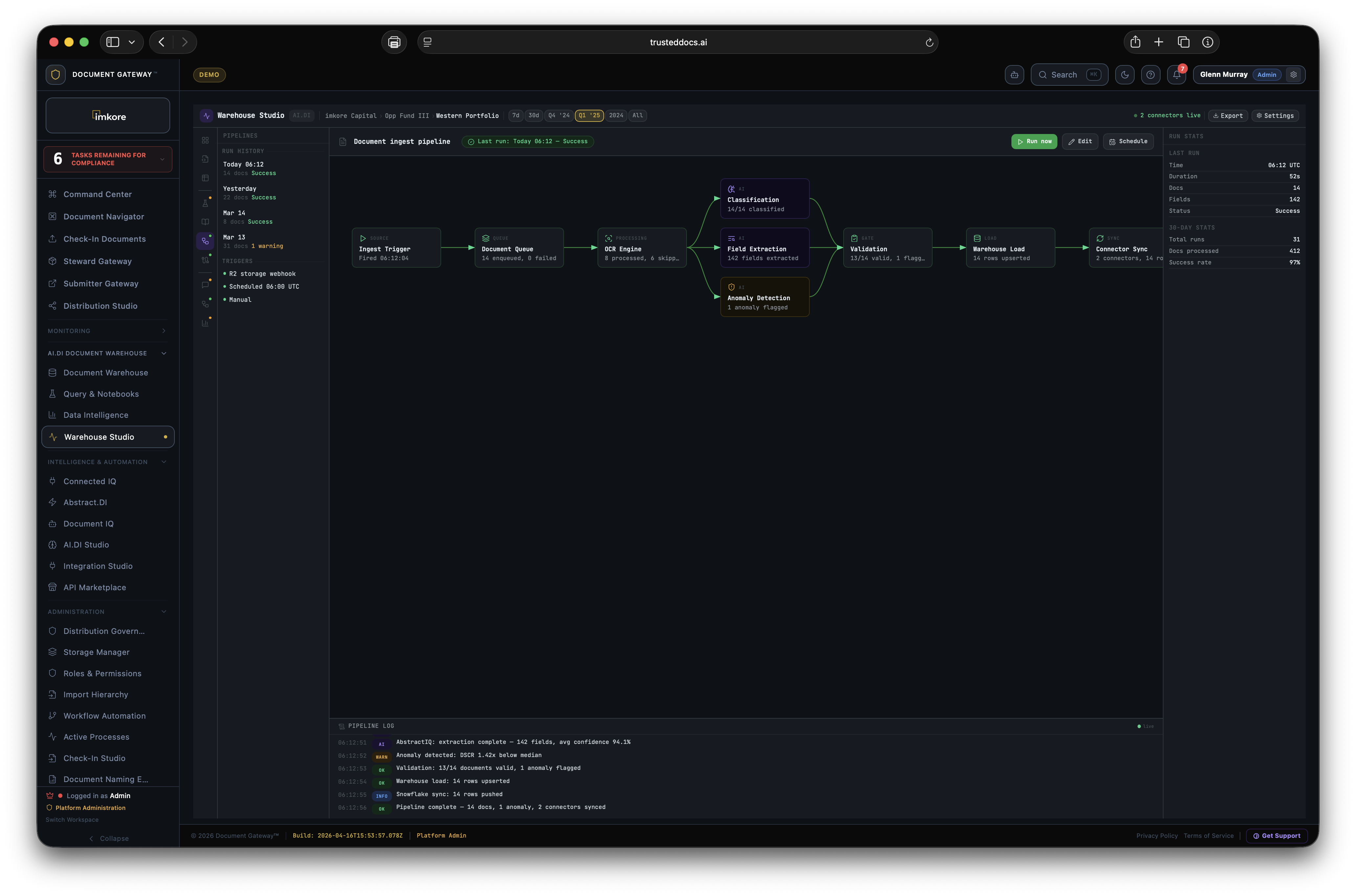
Documents flow into Document Gateway. Abstract.DI extracts intelligence from every one. Sentry fingerprints and certifies them. The Document Warehouse stores all of it as structured, queryable data. The Warehouse makes Abstract.DI more accurate. Better accuracy strengthens Sentry signals. Better signals make Document Gateway more valuable. More value drives more documents. After eighteen months you have an intelligence asset that no incumbent platform can offer at any price, because none of them are built to produce it.
Document Intelligence is the discipline of treating every document your organization depends on as a certified, extracted, queryable, and routable asset. It replaces the thirty year old Store, Organize, Search model with a continuous loop of trust, structure, and distribution built for the way your AI agents actually work. The documents that run your business stop being closed files. They become open intelligence your people, your systems, and your AI can act on.
Any vendor that claims to deliver Document Intelligence must ship all four layers. Today, almost none do. IDP vendors ship Layer 1. Storage platforms ship a partial Layer 4. Nobody else ships Layers 2 and 3. AI.DI ships all four, standalone or integrated.
Every layer of the Framework is a complete product in its own right. Enterprises rarely buy all four on day one. Every enterprise realizes it needs all four by year two. The compounding value of Document Intelligence only arrives when the four layers run as one. Extraction you can trust. Certification tied to structured data. Data accessible to agents. Routing that carries certified records to every system that needs them.
| Vendor | Layer 1 · Extraction | Layer 2 · Certification | Layer 3 · Warehouse | Layer 4 · Orchestration | Complete Framework? |
|---|---|---|---|---|---|
| AI.DI | Abstract.DI | Sentry | AI.DI Warehouse | Document Gateway | Yes, all four |
| Abbyy | Core product | None | None | None | Layer 1 only |
| Hyperscience | Core product | None | None | None | Layer 1 only |
| Datamatics | Core product | None | None | None | Layer 1 only |
| Iron Mountain | Services led | None | None | Records management | Partial 1 and 4 |
| Box | None | None | None | Storage + workflow | Partial 4 only |
| SharePoint / M365 | Copilot wrapper | None | Graph (partial) | Teams integration | Partial 1, 3, 4 |
| M-Files | Aino (training) | None | None | Workflow | Partial 1 and 4 |
| Egnyte | None | None | None | Hybrid storage | Partial 4 only |
Ranks extraction vendors. Covers Layer 1 only. The MQ is useful for extraction RFPs and Abstract.DI belongs on that shortlist. It does not rank certification, queryability, or routing, so it cannot evaluate a Document Intelligence Framework.
Ranks storage and collaboration platforms. Covers Layer 4 partially and nothing else. No CSP vendor ships Layers 1, 2, or 3 as a native capability. Microsoft 365 has the closest partial pattern. Copilot touches Layer 1 and Graph touches Layer 3. Neither is a complete Document Intelligence engine.
There is no Gartner, Forrester, or IDC ranking for the complete Document Intelligence Framework, because the category has not yet been formally drawn by the analysts. AI.DI is the first platform built to deliver it. If you are evaluating document platforms today, the ten questions above give you a cleaner evaluation than any analyst category currently can. The ones that eventually arrive will rank the same four layers this page defines.
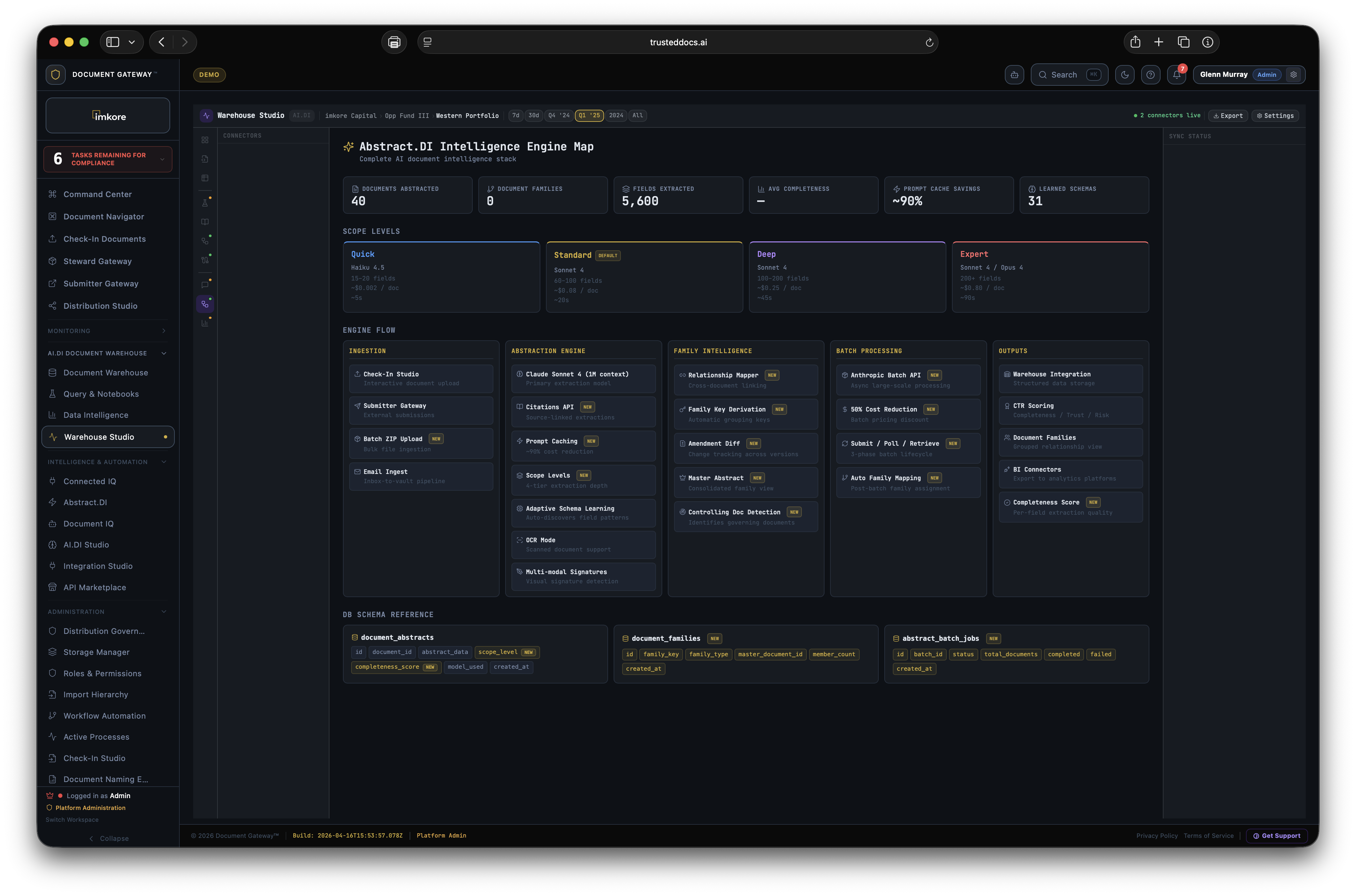
Other vendors talk about AI on slides. AI.DI shipped it. Right now you can use 200+ React and TypeScript components, 29 live serverless edge functions, an ML Learning Studio with 30 self improving engines, a production MCP server, an AI Agent Gateway connecting to Claude, Copilot, GPT, and Gemini, and the AI.DI Studio running 27 active AI engines at the same time. This is the framework you have been waiting for. It exists. It is running. It is yours from day one.

The HITL Reduction engine watches every other AI engine in the platform and quietly promotes classifications to auto approve as confidence climbs above your configured thresholds. Standard document types trend toward zero human review at twelve months. Edge cases and novel documents still surface to a human, because the goal is not zero humans. The goal is the right humans reviewing only the documents that actually need them.




Every legacy document system runs on fixed classification models that require expensive, time consuming retraining projects. The AI.DI ML Learning Studio is the opposite. Thirty engines improve continuously from your own production data, automatically, with zero engineering intervention required. AI.DI gets cheaper and more accurate the longer you use it. The longer you wait, the bigger the lead becomes.
| Tier | Focus | Example Engines | HITL Trajectory |
|---|---|---|---|
| Tier 1 — Foundation | Document type classification | Enterprise Type Classifier, PE Type Classifier, Legal Type Classifier | Near-zero for covered types |
| Tier 2 — Entity | Named entity extraction | Party Extractor, Property Identifier, Fund/Entity Linker | 5–15% at 6 months |
| Tier 3 — Date & Validity | Temporal signal extraction | Expiration Detector, Effective Date Parser, Renewal Classifier | Near-zero for standard formats |
| Tier 4 — Financial | Financial data extraction | Loan Terms Extractor, Critical Data Extract Parser, Appraisal Value Extractor | 10–20% at 6 months |
| Tier 5 · Compliance | Compliance validation | Coverage Gap Detector, Compliance Flag Engine, Signature Validator | 15 to 25%. Domain expertise retained. |
| Tier 6 · Cross-Document | Cross-document consistency | Portfolio Benchmark Engine, Anomaly Correlator, Reconciliation Engine | Complex analysis. Strategic HITL. |
Every platform in this matrix was built to hold documents, not to understand them. Box, SharePoint, M-Files, and Egnyte all share the same constraint. Their data model was drawn before anyone had heard of an LLM, and they cannot rewrite it without breaking every customer already running on the old model. Every dollar they spend on AI is spent on top of that constraint. Every dollar you spend with AI.DI is spent free of it. That is why the gap between what a document platform can do and what your business actually needs keeps widening.
| Capability | AI.DI Platform | Box | SharePoint | M-Files | Egnyte |
|---|---|---|---|---|---|
| Architecture & Philosophy | |||||
| AI native architecture (built for AI, not adapted) | Win 2024-2025. Zero compromise. AI is core, not a wrapper. | Bolt-on | Copilot wrapper | Aino, improving but bolted on | Minimal |
| Zero legacy technical debt | Win No codebase older than 18 months. | 2005 origin | 2001 origin | 2003 origin | 2009 origin |
| Edge compute architecture | Win All compute at edge. Scale to zero or infinity. | None | Azure Functions (partial) | None | None |
| Modular adoption (standalone or full suite) | Win Every engine has standalone value. | Partial | Module-based but complex | Partial | Partial |
| AI & Document Intelligence | |||||
| Structured data extraction from documents | Win Abstract.DI. Any type, 94% day one, 100K batch. | None | Basic Copilot extraction | Aino, requires training | None |
| Day one extraction accuracy (no training) | Win 94%+ on prebuilt schemas. No training required. | N/A | N/A | Months of training | N/A |
| GPU accelerated OCR pipeline | Win DocTR. 10 to 50x speedup on GPU. | None | Azure OCR (limited) | Basic OCR | Basic OCR |
| Batch processing (100K+ archives) | Win 100K-chunk batch. ZIP, Box, SharePoint, S3. | None | None | Limited batch | None |
| 30 self improving ML engines | Win Continuous production learning. No ML engineers. | None | Generic Copilot | Limited self-learning | None |
| HITL Reduction AI (autonomous meta-engine) | Win Autonomous promotion of high-confidence classifications. | None | None | None | None |
| Trust, Compliance & Security | |||||
| Document fingerprinting (deterministic mathematical proof) | Win Thousands of prebuilt fingerprints. Zero document storage required. | None | None | None | None |
| Zero document storage compliance model | Win Only fingerprints stored. GDPR minimization by math. | Full storage | Full storage | Full storage | Full storage |
| PII auto detection and redaction pipeline | Win Tokenization pipeline auto redacts at ingestion. | None | Purview (partial) | None | DLP (partial) |
| Fraud / document manipulation detection | Win Deterministic. Single character change detectable. | None | None | None | None |
| Blockchain audit trail | Win On chain anchoring. 2,814+ documents on chain. | None | None | None | None |
| Data & AI Infrastructure | |||||
| Structured document intelligence warehouse | Win Every extracted field is a queryable row. Unique. | None | None | None | None |
| Snowflake Data Share (zero ETL) | Win Zero-copy. Join doc intelligence with financial data. | None | None | None | None |
| MCP server for AI agents | Win Production MCP. Claude, Cursor, LangChain. No wrapper. | None | None | None | None |
| Vector embeddings on certified chunks | Win Tied to certified versions. pg_vector native. | None | Azure AI Search (partial) | None | None |
| CTR Score (Continuous Transaction Readiness) | Win Live composite readiness score. Portfolio-wide. | None | None | None | None |
| 27 active AI engines in production | Win AI.DI Studio. Live engine map with real time status. | None | None | None | None |
| Deployment & Integration | |||||
| Unlimited hierarchy depth (any org structure) | Win Enterprise → Group → Entity → Asset → Unit. Any depth. | Folders only | Sites/subsites | Metadata based | Folders/workspaces |
| 30 day deployment (no implementation project) | Win 30 days from contract to live. M-Files runs 3–6 months. | Weeks–months | Months–years | 3–6 months typical | Weeks–months |
| Installed base / existing trust relationships | Win 45 FileStar enterprise clients. 20+ year relationships. Zero CAC. | Large (hard to access) | Large (bundled) | Existing clients | Existing clients |
Abbyy, Hyperscience, Datamatics, Iron Mountain and the rest of the IDP Magic Quadrant do one thing: they extract fields from documents. Some do it well. None of them ship a trust layer. None of them ship a warehouse layer. None of them ship a routing layer. If you need those — and every enterprise eventually does — you buy three more vendors and wire them together yourself.
| Capability | AI.DI Platform | Abbyy | Hyperscience | Datamatics | Iron Mountain IDP | Egnyte |
|---|---|---|---|---|---|---|
| Layer 1 · Extraction (IDP Baseline) | ||||||
| Day one accuracy without training | Win 94%+ on prebuilt schemas. | Document skills library, tuning required | Supervised ML training required | Template + ML training | Professional services project | Not an IDP product |
| Any document type | Win Ground up on prebuilt schemas. | Win Mature catalog | Win Supervised | Win Template based | Structured / semi structured | None |
| GPU accelerated OCR (10–50x) | Win DocTR native · edge compute. | CPU pipeline | CPU pipeline | CPU pipeline | Varies by engagement | Basic OCR |
| Batch scale (100K+ archives) | Win 100K chunk batch native. | Win Enterprise scale | Win Volume proven | Partner delivered | Service engagement | None |
| Time to first extraction | Win 30 days from contract to live. | 3–6 months | 3–9 months training | 2–4 months | Service project | N/A |
| Layer 2 · Certification & Provenance (The Missing Trust Layer) | ||||||
| Deterministic document fingerprinting | Win Sentry · mathematical proof. | None | None | None | None | None |
| Row level Trusted Data Fingerprint | Win Unique in market. | None | None | None | None | None |
| Zero storage vaulting / GDPR minimization | Win Only fingerprints stored. | Full storage | Full storage | Full storage | Full storage | Full storage |
| Fraud / tamper detection | Win Single character change detected. | None | None | None | None | None |
| Blockchain anchored audit trail | Win 2,814+ docs on chain. | None | None | None | None | None |
| Layer 3 · Queryable Intelligence Warehouse (The Missing Data Layer) | ||||||
| Extracted fields queryable in Postgres | Win Every field is a row. | CSV / JSON export | CSV / JSON export | CSV / JSON export | CSV / JSON export | None |
| Snowflake zero copy data share | Win Zero ETL join with financial data. | None | None | None | None | None |
| BI connectors (Tableau, Power BI, Databricks, dbt) | Win Native via MCP. | Via export | Via export | Via export | Via export | None |
| MCP server for AI agents | Win Production MCP. | None | None | None | None | None |
| Layer 4 · Orchestration & Routing (The Missing Distribution Layer) | ||||||
| Transaction rooms / secure distribution | Win Native. | None | None | None | Records management only | Hybrid storage |
| Multi system connectors (SharePoint, Box, ERP) | Win 28+ connectors. | Partner ecosystem | Partner ecosystem | Partner ecosystem | Win Services integration | Win Storage integrations |
| Continuous readiness scoring (CTR) | Win Portfolio wide live score. | None | None | None | None | None |
| Strategic Fit | ||||||
| Category | Document Intelligence Platform | IDP Leader | IDP Leader | IDP + BPM Services | Records + IDP Services | Hybrid Storage |
| Core go to market | Certified, queryable document asset | Enterprise extraction | ML led high volume extraction | Managed services + tooling | Services led IDP + physical records | Content collaboration |
| In house ML team required | No Day one prebuilt. | Often | Yes | Partner led | Partner led | N/A |
Abstract.DI competes head to head with Gartner MQ Leaders like Abbyy, Hyperscience, and the top IDP challengers. On day one accuracy without training, GPU accelerated OCR, and batch scale, Abstract.DI delivers Leaders class execution. On vision, prebuilt 94 percent schemas on any document type redefine what day one IDP should look like. If the only box you need filled is the IDP box, Abstract.DI belongs on your shortlist.
The Magic Quadrant ranks extraction. It does not rank certification, queryability, or routing, because no existing IDP vendor delivers those layers. AI.DI delivers every one of them as one platform. The IDP MQ cannot rank what the category has not yet drawn. Enterprises buying from today's MQ will still need three more vendors by next year. Enterprises buying AI.DI already have all four.

















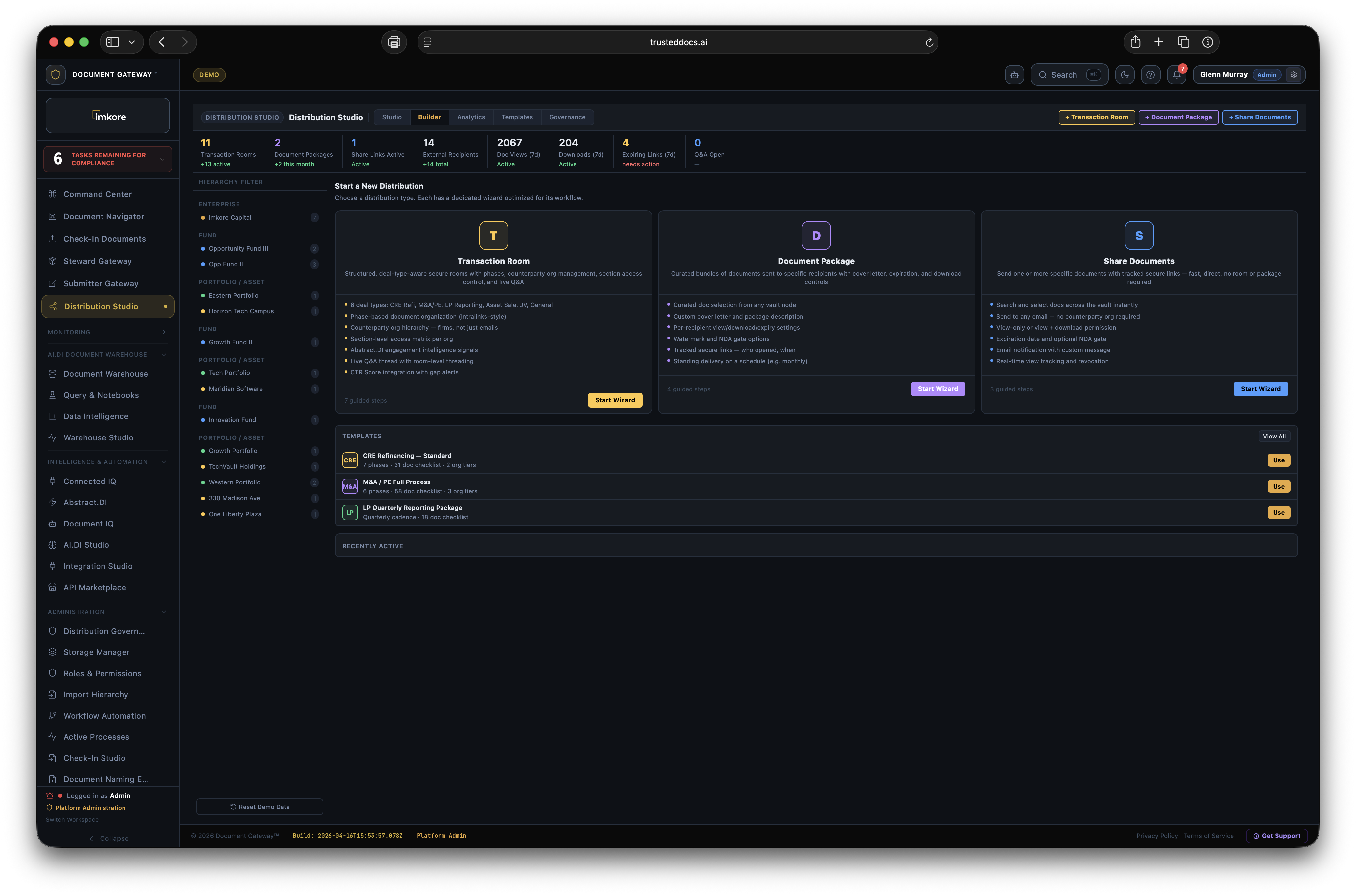
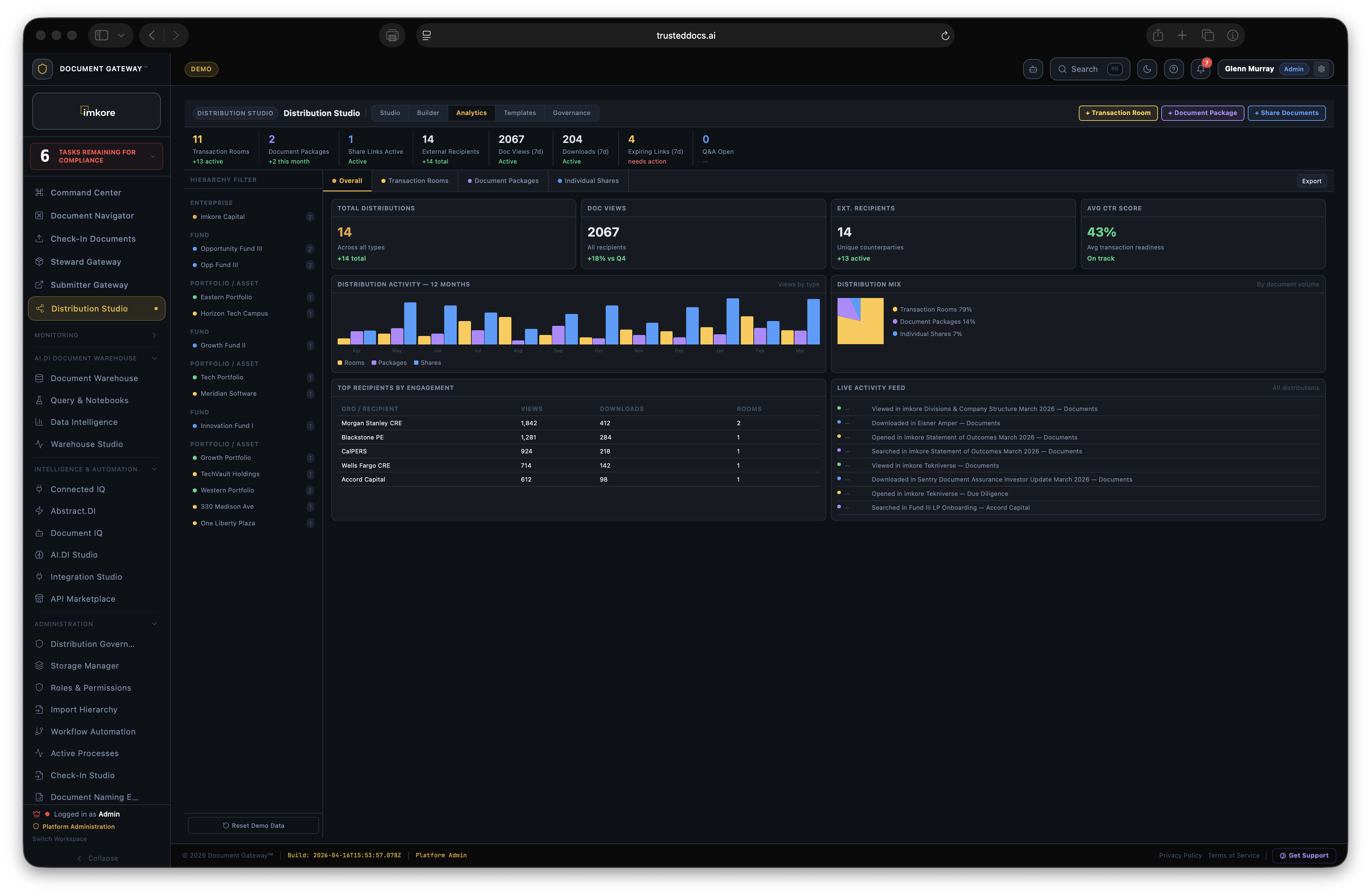
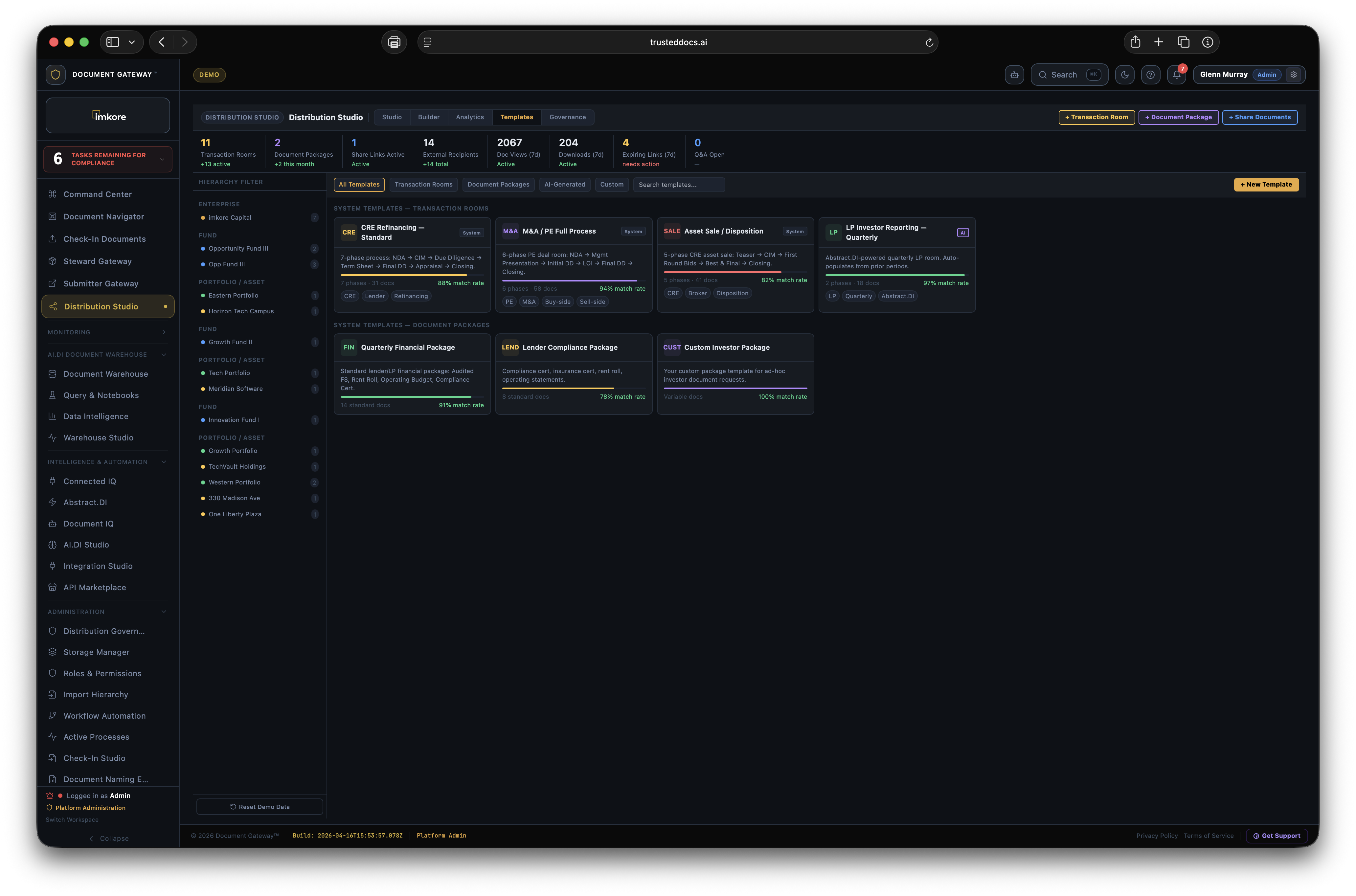
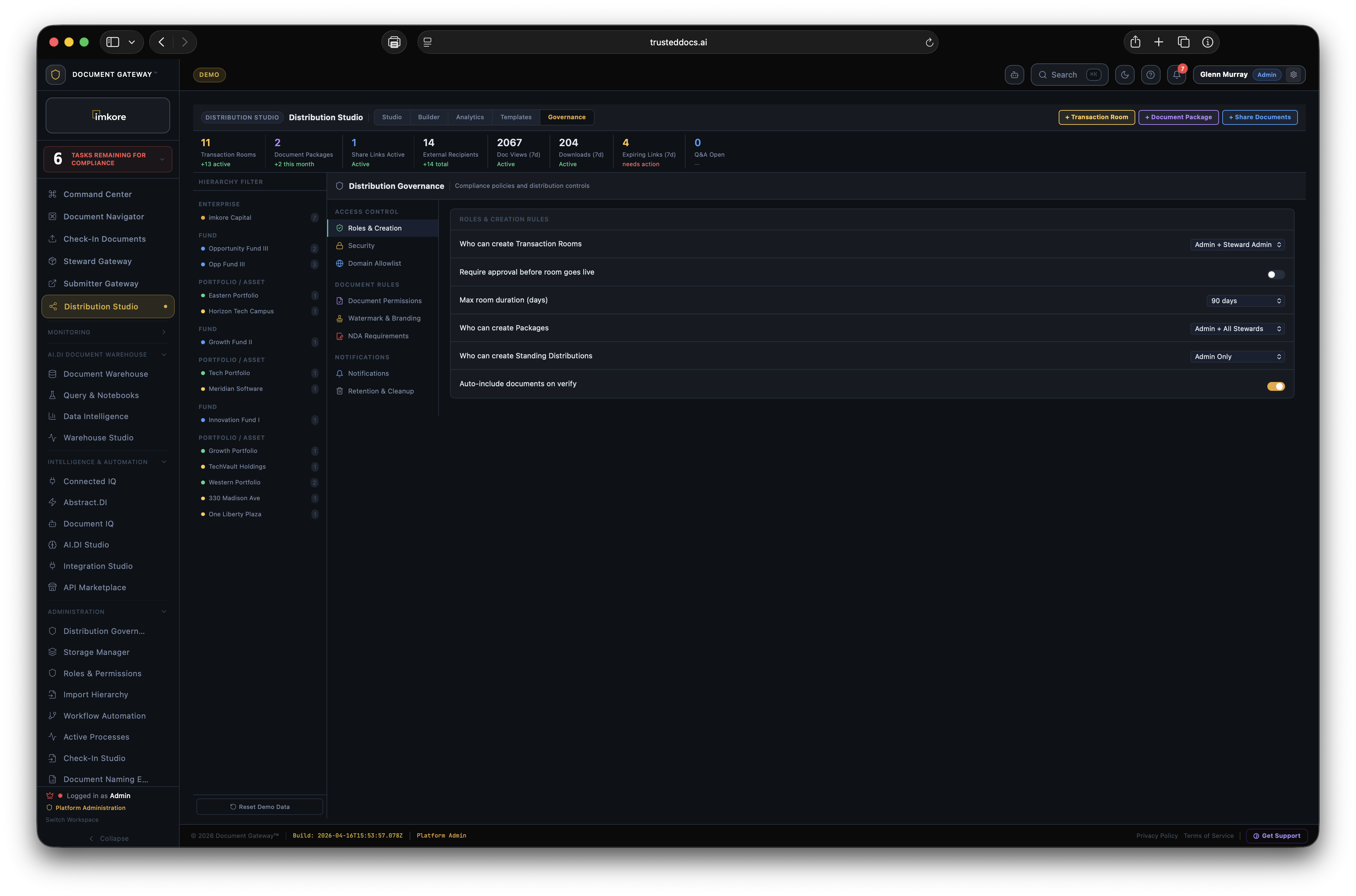
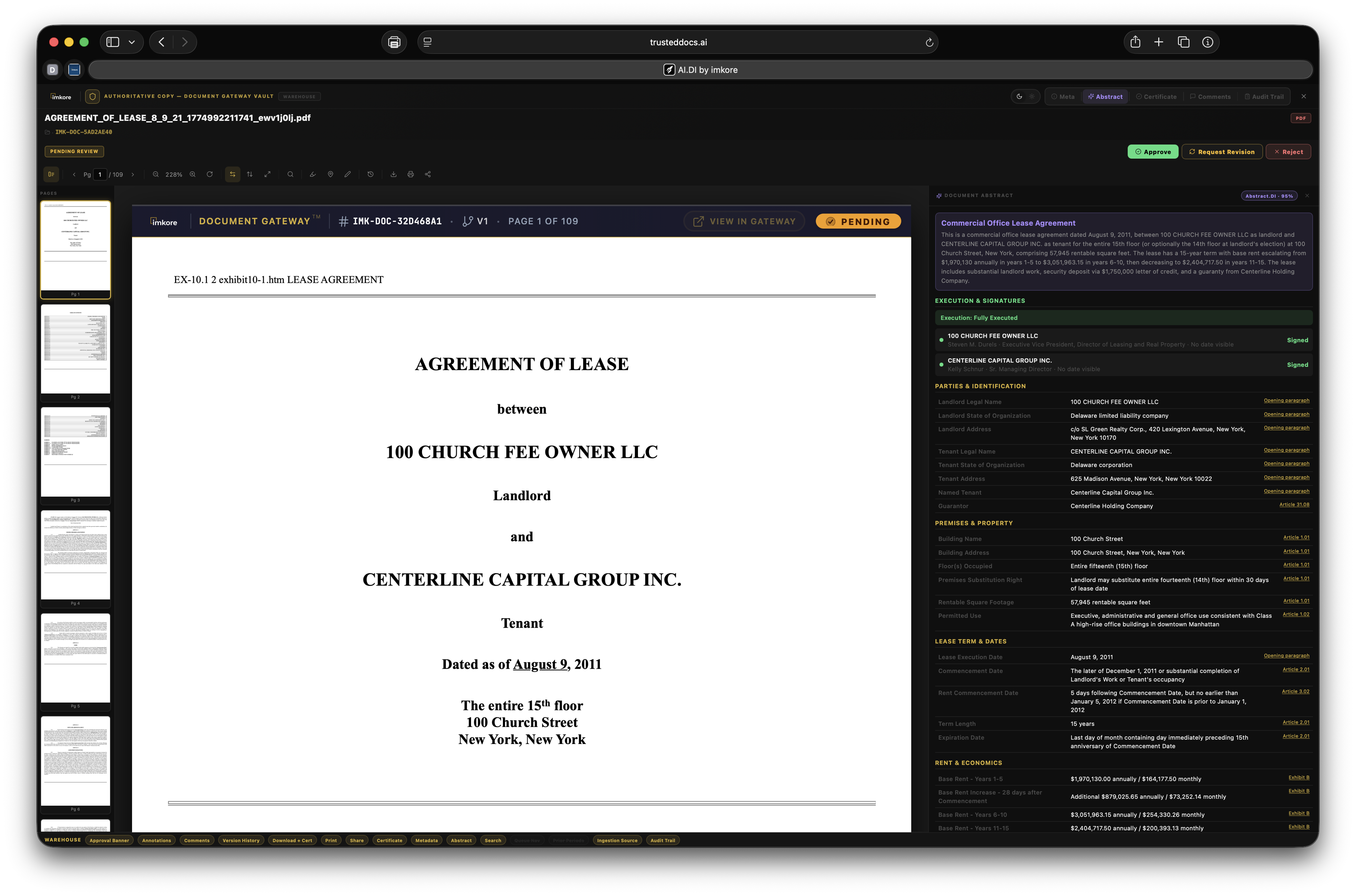
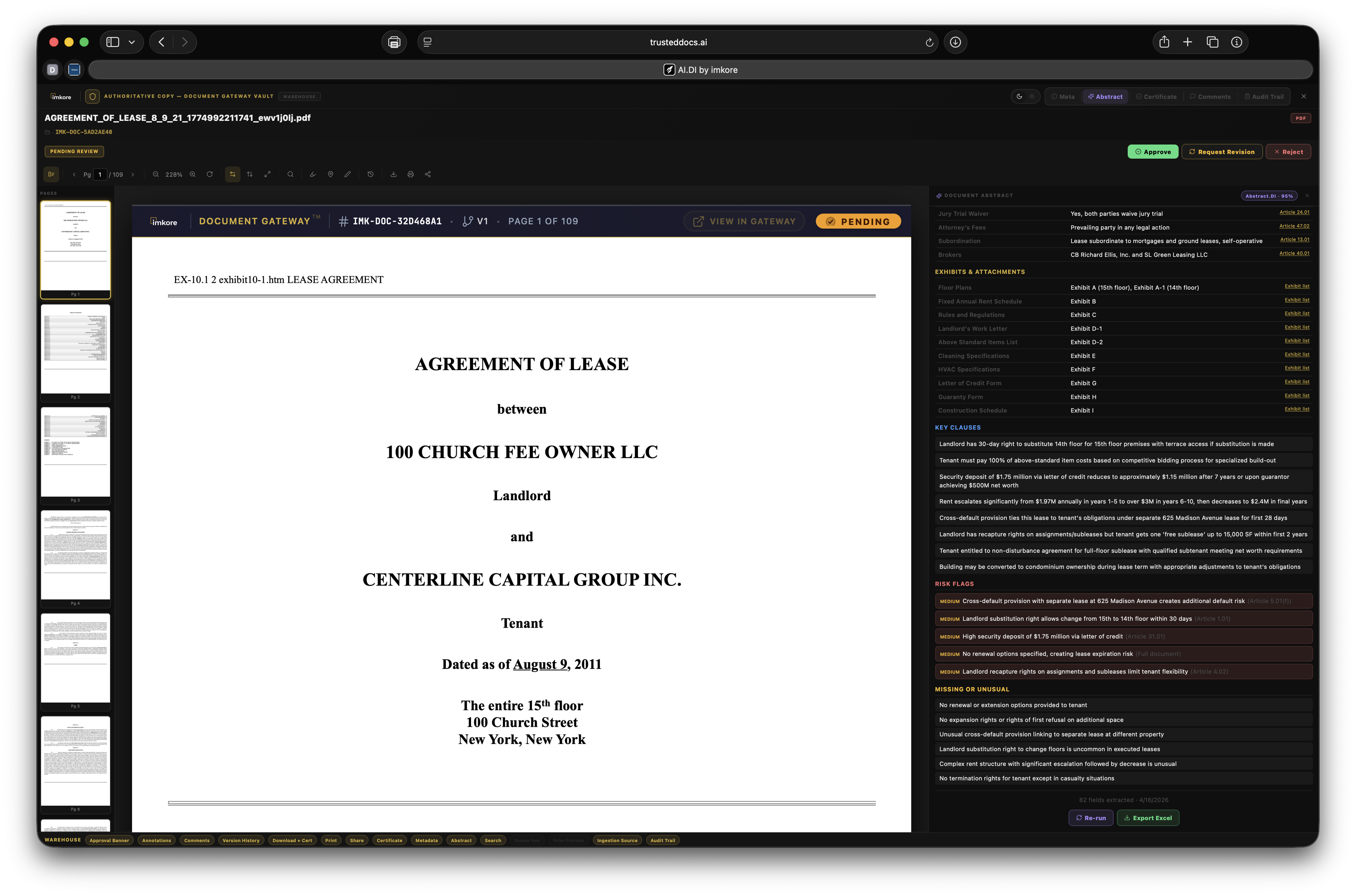
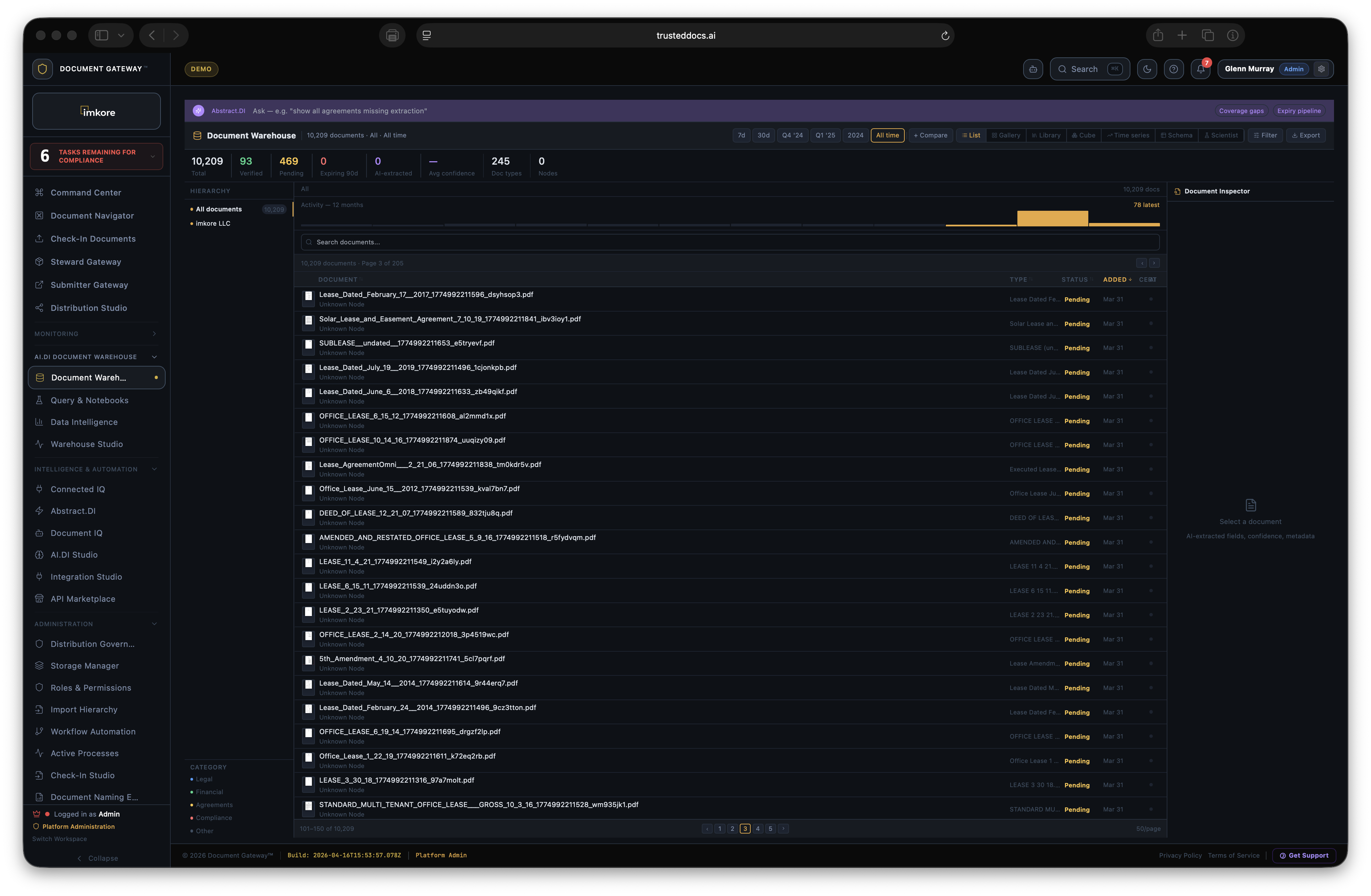
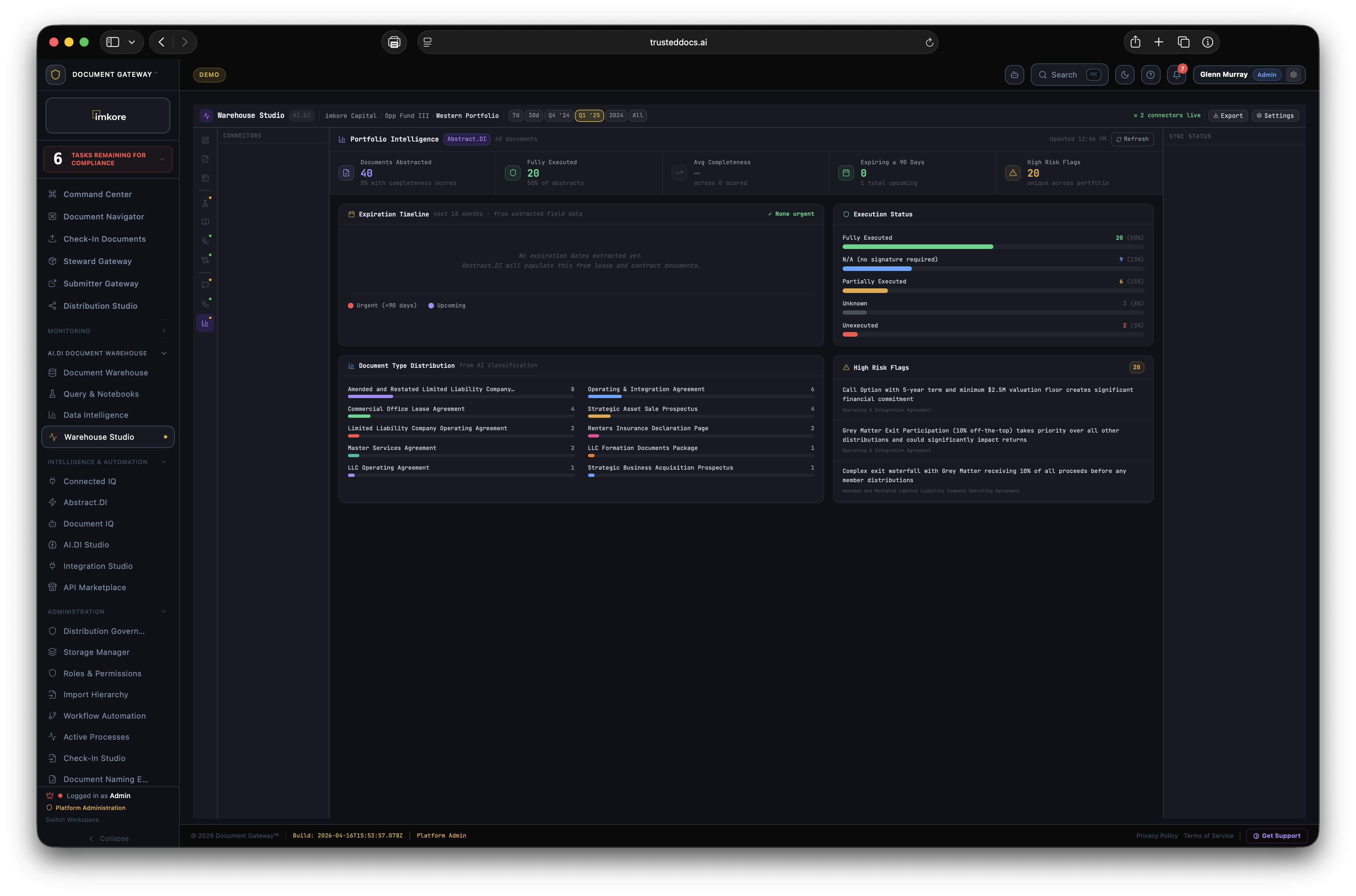
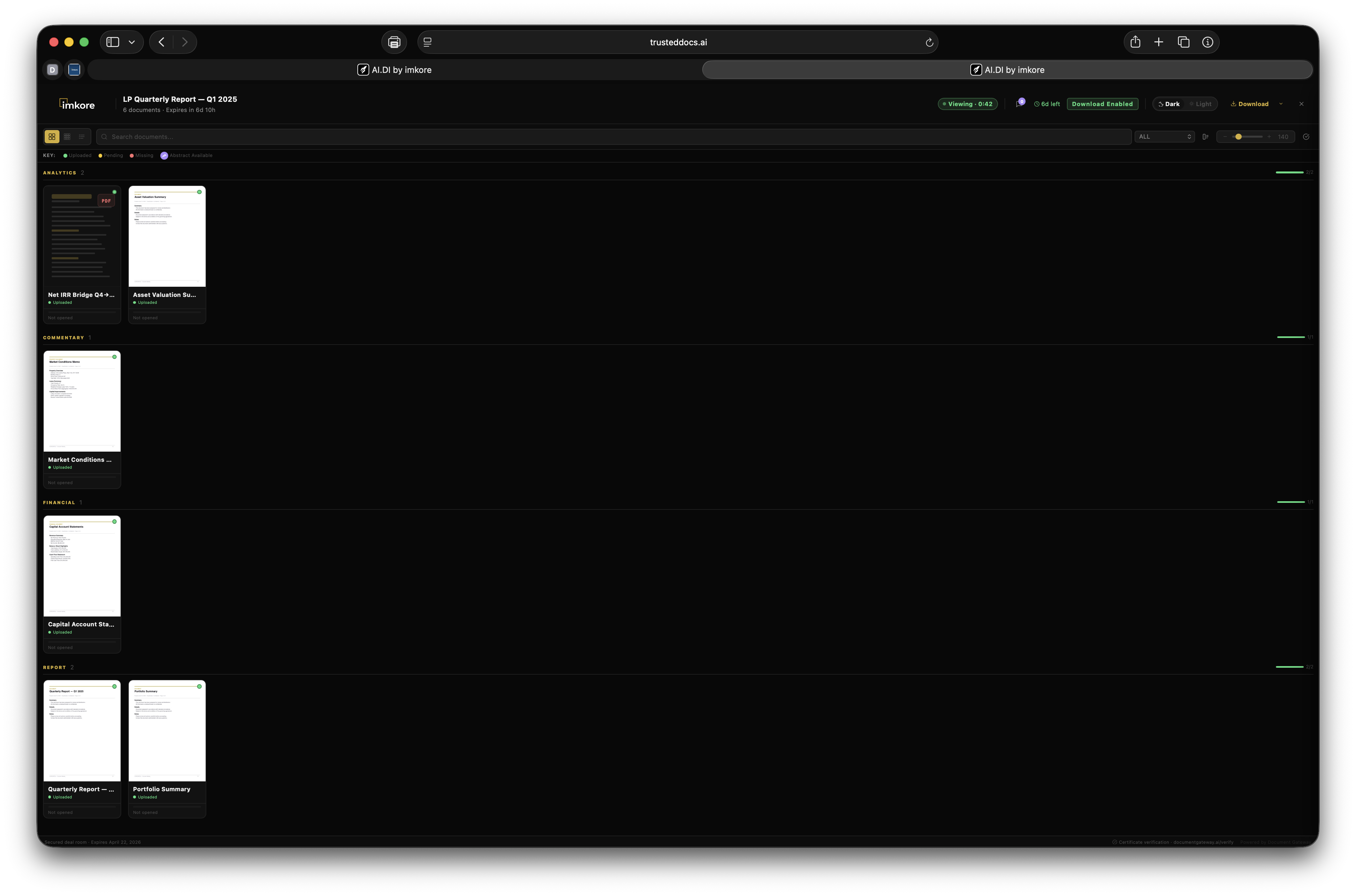
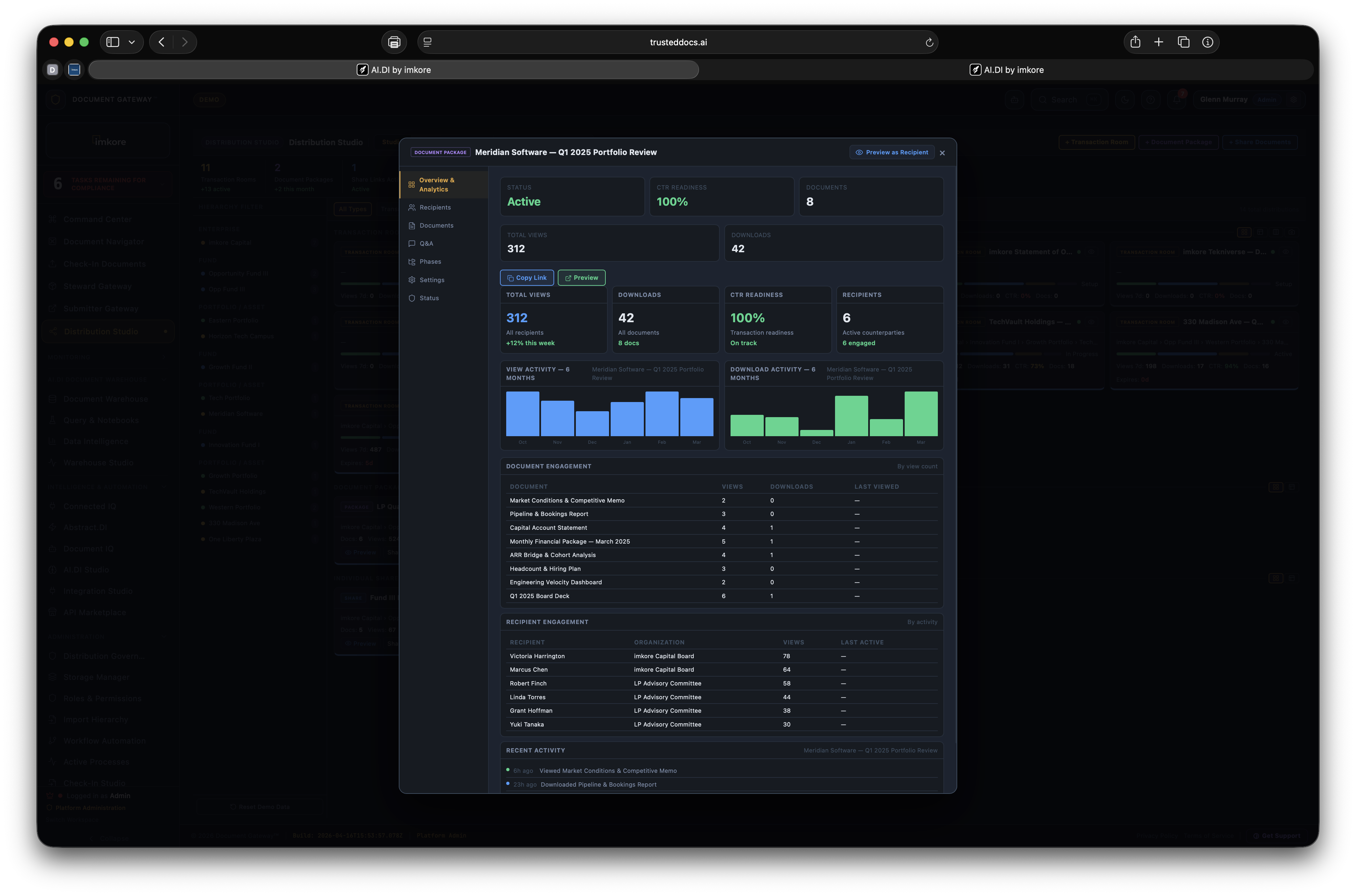
Every transaction ready organization has the same invisible problem. Thousands of critical documents that no one has truly read. Leases. Loan agreements. Operating agreements. Amendments. Certificates. They sit in folders, filed correctly, but essentially opaque. When a lender asks "is the lease fully executed," someone has to open it and look. When a deal team needs all expiring leases for a portfolio review, someone spends a weekend building a spreadsheet. When a counterparty receives a document package, they get files, not understanding. Document Gateway changes this. We built a platform where every document that enters your organization gets read, understood, and acted upon, automatically. Compliance monitors itself. Distributions assemble themselves. Counterparties receive context, not just files. The scramble is over.
Most platforms that touch documents store them. A few extract surface metadata. None of them connect extracted intelligence to automated distribution and continuous compliance at this depth. The combination of amendment chain recognition, expiry date extraction from real document content, execution status tracking across the portfolio, recipient facing intelligence, and rules driven autonomous distribution is not available anywhere else. It is the difference between a document repository and a Document Intelligence framework. A system where every document that enters is understood, and that understanding drives everything downstream.
The Steward defines the documents that matter. What is required. Who must submit. When it is due. What rules apply.
Packaged as a Submission Package
Submitters open one branded portal designed for them. Drag and drop. Nothing more. The framework handles everything else, automatically and intelligently.
CTR Score · Always Live
Open a Transaction Room. Share a link. The document never leaves your vault. The counterparty sees the live, certified, current version. Always.
Link, Not a Copy
The Steward owns every document requirement, every submitter assignment, every distribution decision. Full visibility. Full control. Full intelligence at the fingertips.
Access · Full Platform
The Submitter receives a single purpose portal link. They see exactly what is required of them. Nothing more. No account. No training. No friction.
Access · Portal Only
The Counterparty receives a link, not a file. They view documents in place, always current, always certified. Their access is time limited and every interaction is tracked.
Access · Transaction Room
Every file enters a multi-stage AI pipeline before a human sees it. Abstract.DI classifies the document type, extracts key fields, scores confidence at the field level, checks for duplicates, detects anomalies, and routes to the correct steward queue automatically.
Three distribution modes with full audit trails and recipient access controls. Every document leaves the platform certified and tracked.
A purpose built external submission portal that presents to counterparties as your own branded platform. No account creation required for submitters.
Real time operational view across the entire document corpus by entity, by division, by document type, or by compliance obligation.
Five-tier organizational hierarchy providing structured, queryable document storage with role-enforced access at every level.
Configurable multi-step approval chains for any document type or business process. Every workflow is auditable end to end.
Every user action in Document Gateway is governed by a five-role permission model enforced at both the application and database layers via Supabase row-level security policies.
Zero legacy code. Entirely 2024 to 2026 stack designed for sub-30-day enterprise deployment.
Single-tenant, multitenant, Azure Cloud, AWS, on-premise, and hybrid deployments are all supported. Any file type. Any industry. Any org size. Average enterprise deployment: 30 days from contract to go-live. No professional services required for standard configurations.
Most platforms that touch documents store them. A few extract surface metadata. None of them close the loop between the intelligence inside a document and the actions that intelligence should drive across the rest of the organization. We built Abstract.DI to end that gap. Every document that enters your platform becomes structured intelligence the moment it arrives, and that intelligence flows everywhere it needs to go automatically. Approvals. Distributions. Compliance. AI agents. Counterparty experiences. Workflows. Everything downstream just works, because every document is finally understood.
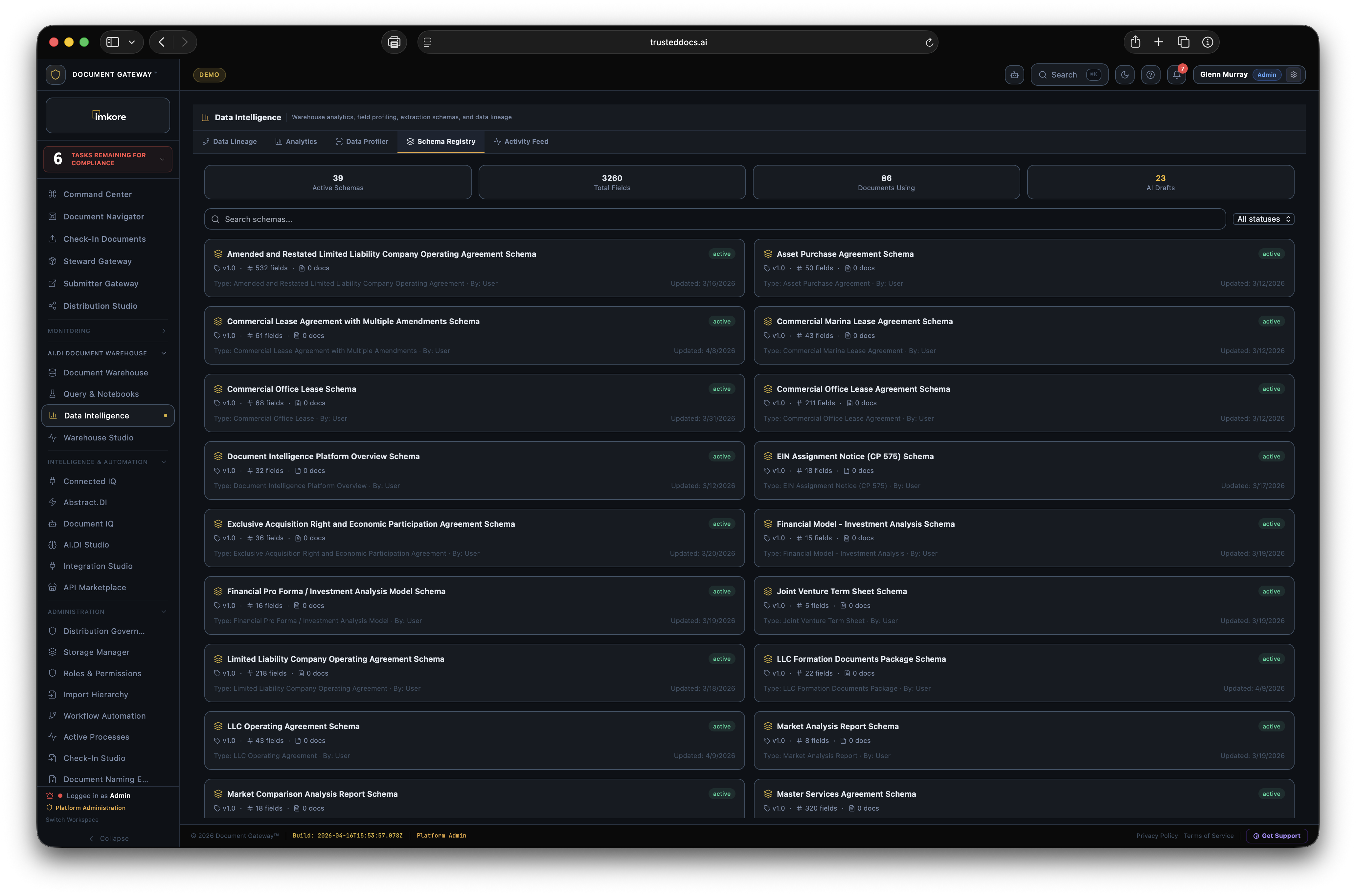
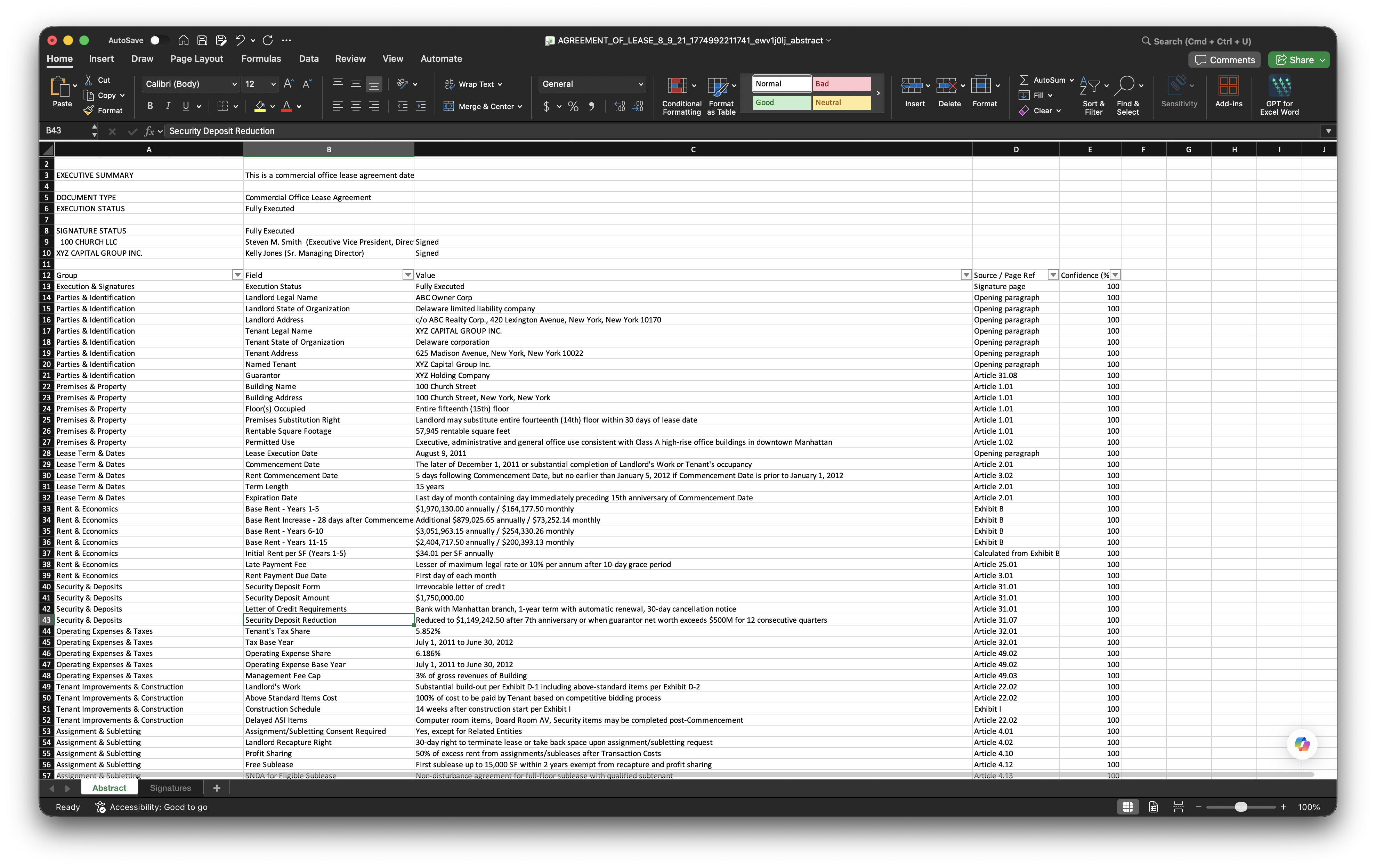
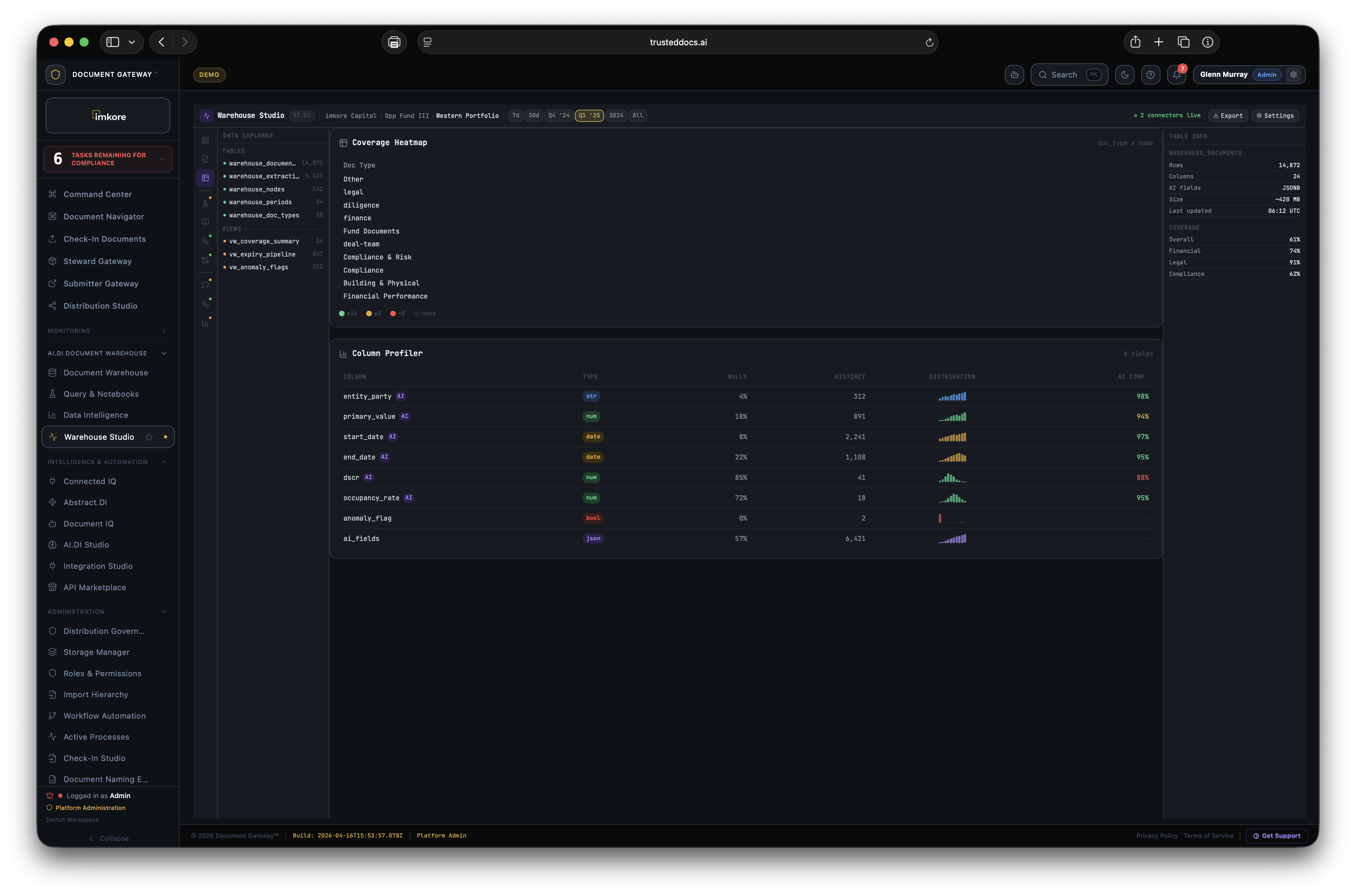
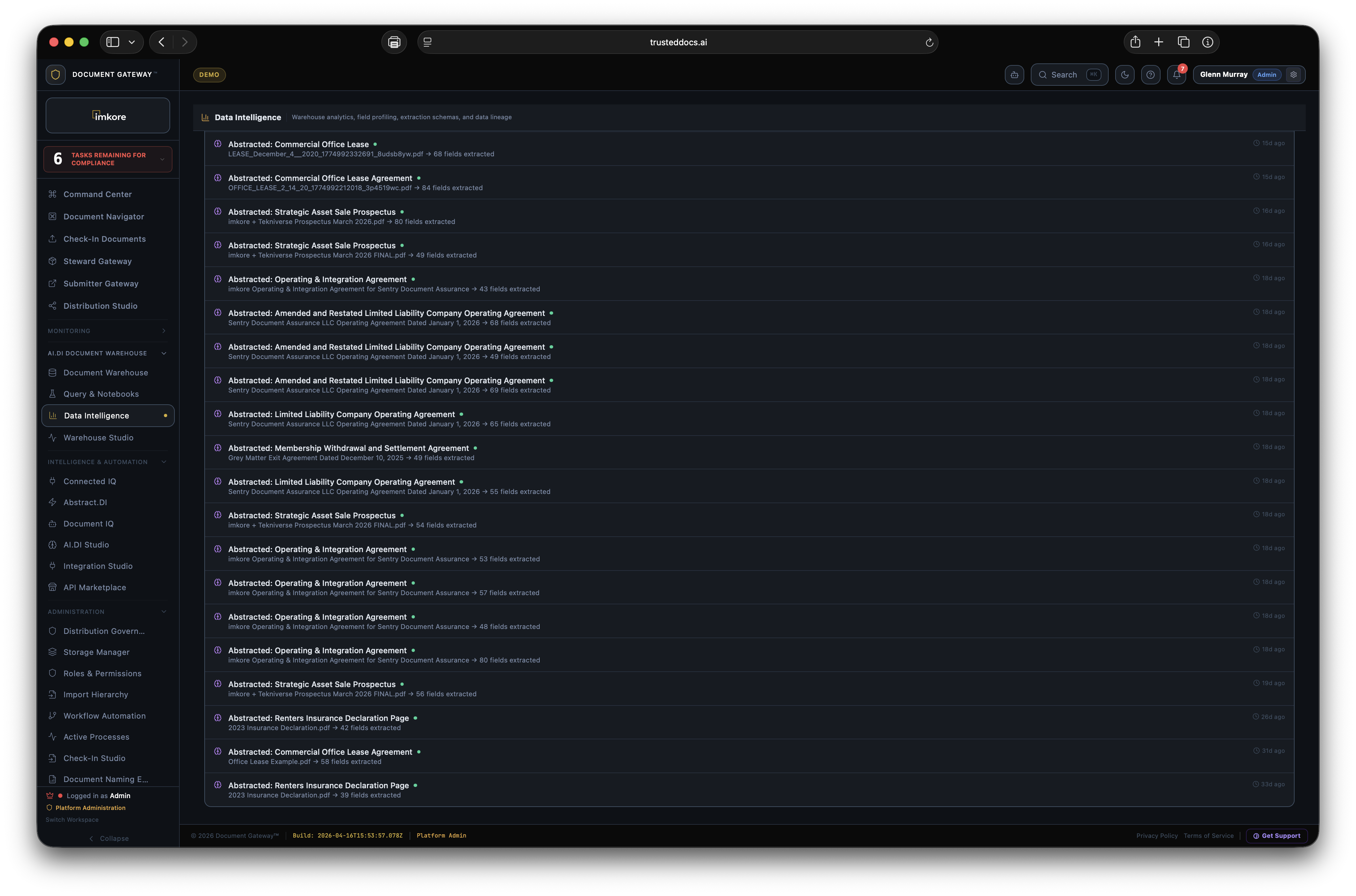
Extracted from every document type regardless of content: node_path, hierarchy_path, doc_type, workflow_status, added_at, original_name, storage_path, period. These fields form the backbone of the Document Warehouse schema and enable cross-entity search across the entire corpus.
Present for documents where Abstract.DI has completed extraction: ai_fields (JSONB), extraction_confidence (numeric 0 to 100), entity_party (primary counterparty), primary_value (lead financial figure), start_date, end_date. These fields are present across a standard deployment corpus of thousands of documents.
Extracted from financial statements, loan documents, and operating reports: coverage ratios, loan-to-value metrics, net operating income, revenue, net income, return metrics, and performance multiples. All numeric fields stored with full precision for direct BI tool consumption without transformation.
Extracted from contracts, utilization reports, and entity records: utilization_rate, total_units, primary_counterparty, anomaly_flag (boolean — AI detected discrepancy). The anomaly flag is computed by comparing extracted values against corpus patterns. A coverage ratio of 0.4 in a corpus where the median is 1.8 raises the flag automatically.
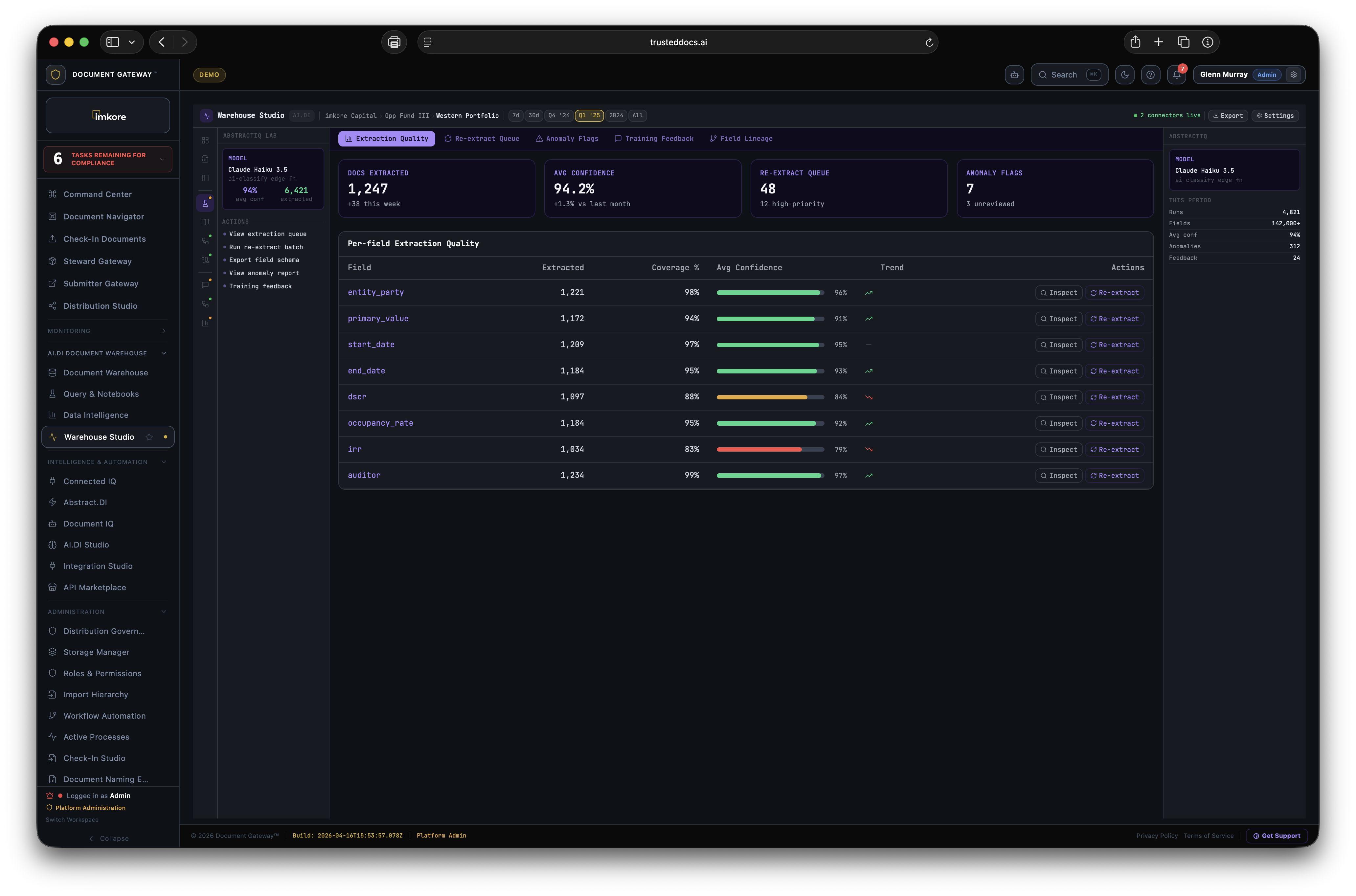
Abstract.DI maintains per-tenant model statistics that improve continuously as stewards interact with the platform:
Every steward action is a labeled training example. The model does not require separate annotation workflows or data science involvement.
Abstract.DI ships with prebuilt schemas for over 5,700 document types across industries. For document types outside the standard taxonomy, the Custom Schema Builder lets admins define extraction targets directly. Specify the fields you need, provide three to five example documents, and the model learns the pattern. No code. No data science team. New document type schemas are typically operational within one business day.
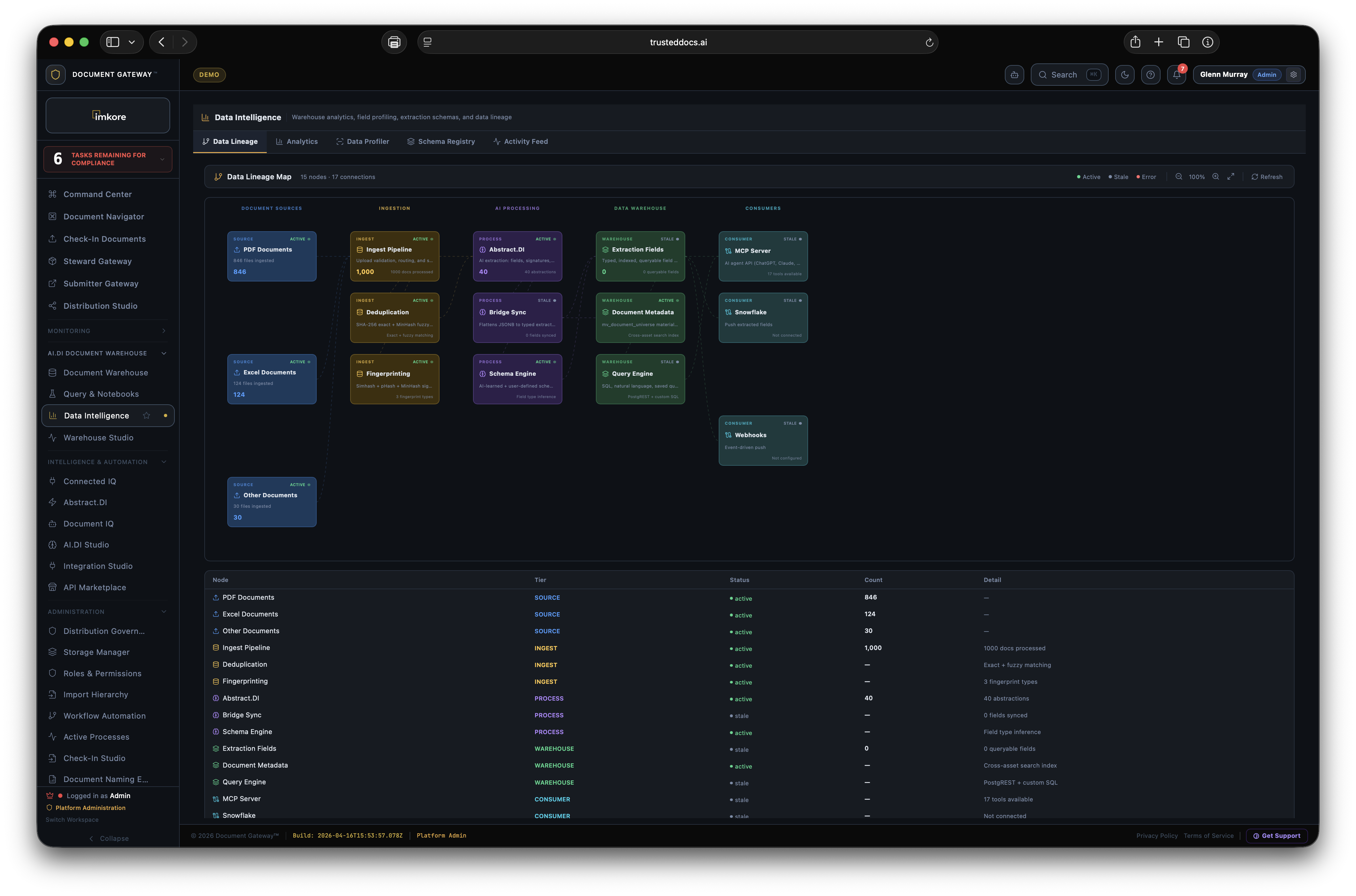
Every organization runs ten or twenty or fifty different systems that hold documents. Nobody knows what is real, what is current, what is duplicated, or what is missing. Asking a simple question like "where is the latest signed version of this contract" turns into a multi day scramble across teams and systems. Sentry was built to end that, permanently. Connect every system once. Search like Google forever. Sentry becomes the unified document intelligence overlay across your entire organization without you having to move a single file.
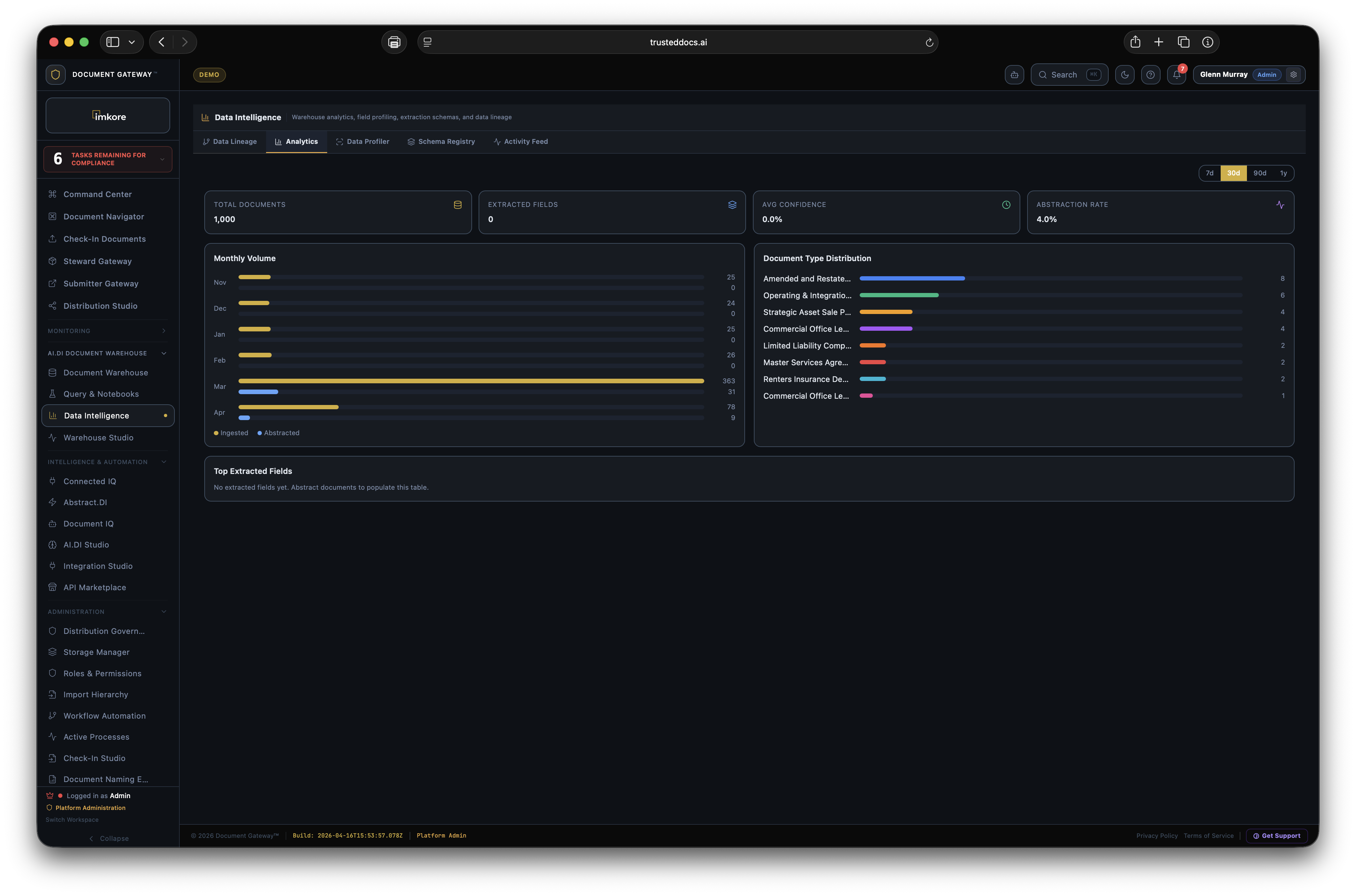
Industry average: more than 40% of the files in any organization are duplicates. A document estate with 40% duplicates means 40% of every AI invoice computes the same content twice. Sentry identifies every duplicate across every connected system, consolidates them to canonical records, preserves all metadata from every duplicate instance, and quietly suppresses the duplicates from AI processing queues. AI compute costs drop 30 to 50% on day one. Your prompts do not change. Your models do not change. The duplication just goes away.
Live analytics on documents across every system. By source. By format. By status. By owner. Sentry shows you exactly which documents matter and which do not, where remediation is needed, and where governance is failing.
Decision makers stop guessing. Compliance posture, data quality maturity, and risk exposure become measurable KPIs. Document intelligence becomes a board level metric, not a back office function.
Sentry sees every duplicate across every connected system, all at once. Storage cost, compliance risk, and operational drag from redundant content become quantifiable. Defensible deduplication runs continuously without sacrificing auditability or chain of custody.
The redundancy that has been compounding for a decade gets resolved methodically, automatically, and safely.
Unified discovery of every document across every silo. Sentry surfaces misplaced sensitive content, policy exceptions, and information governance gaps that no single system would ever expose on its own.
Strategic document migration, normalization, and records governance finally have the underlying intelligence to be done correctly, not blindly.
For life sciences and academic clients, Sentry has imported, fingerprinted, and organized roughly thirteen million PubMed abstracts, with hourly update capability against the full thirty nine million record National Library of Medicine corpus.
Industry knowledge bases like this can be added to any client deployment, making Sentry a unified entry point to the documents your organization holds and the published research that informs them.
Sentry registers, processes, and fingerprints every document flowing through Document Gateway in both directions. Documents distributed externally are certified before they leave. Documents received are verified on arrival. Combined with Sentry's universal search across every connected system, your entire document estate becomes one trusted, queryable, fully visible intelligence layer with readiness scores that update in real time. This is the foundation of Continuous Transaction Readiness.
For thirty years, every enterprise ran a document system and a data warehouse in parallel. The document system stored files. The data warehouse stored numbers. The actual information inside the documents (the obligation term, the coverage ratio, the commitment date, the counterparty agreement) lived in neither. It was trapped in PDFs that nobody could query. The AI.DI Document Warehouse ends that separation permanently. Every document is read by Abstract.DI, every field becomes a column, and the warehouse becomes a continuously enriched, AI maintained structured database of everything your organization has ever received, produced, or executed.
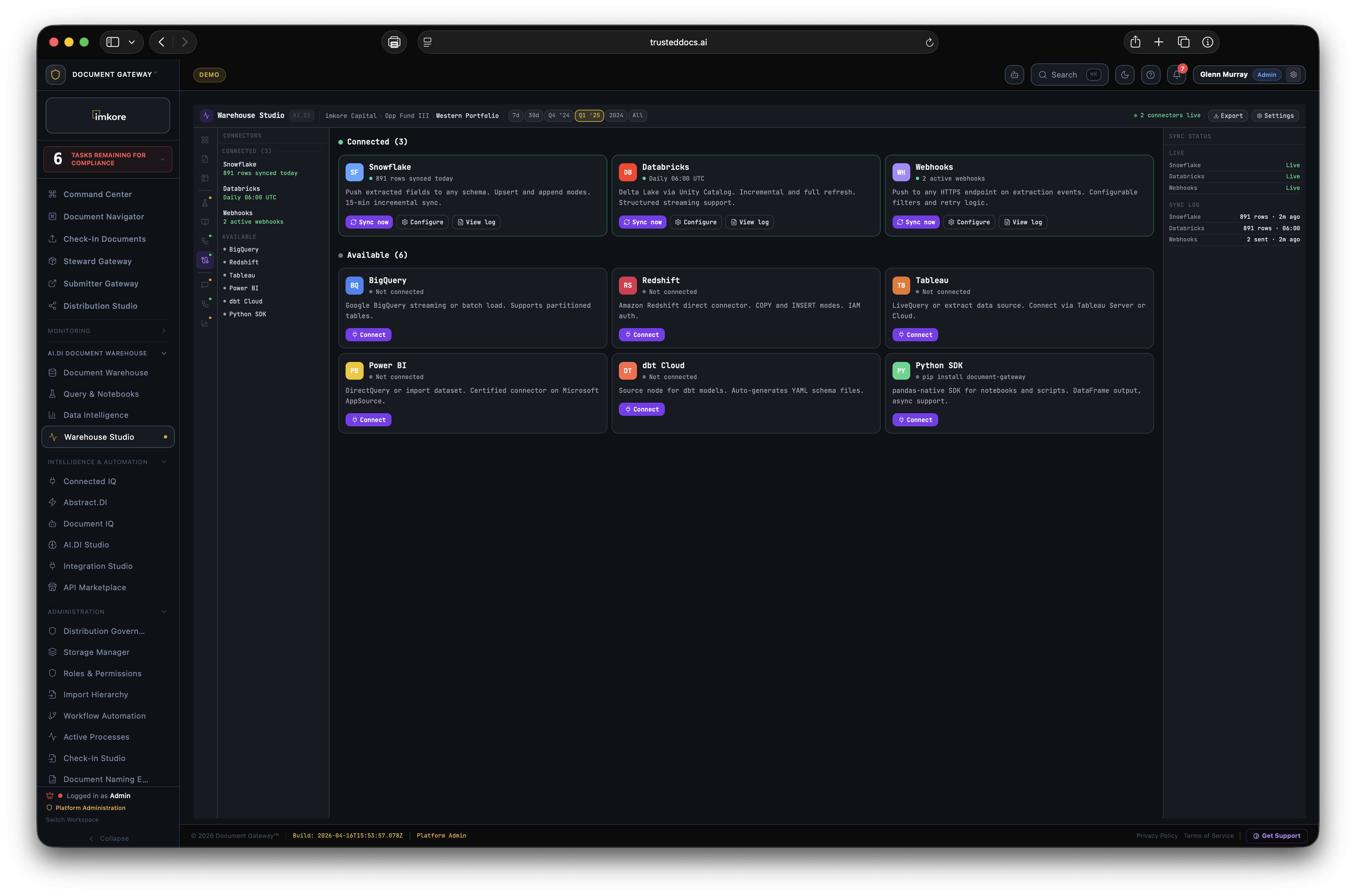
Most document platforms lock your data inside their walls. We do the opposite. The Warehouse runs on PostgreSQL, the most widely used open source database in the world. It speaks SQL. It speaks REST. It speaks GraphQL. It speaks MCP. Every BI tool already knows how to talk to it. Every data scientist already knows how to query it. Every AI agent can connect through the published MCP server. Your Document Intelligence is not held hostage. It is yours, in your stack, accessible to every system you already operate. You can stand up a Snowflake share, push to Databricks, pull from Power BI, and run a Python notebook against the same data, simultaneously. We enable that. The competition does not.
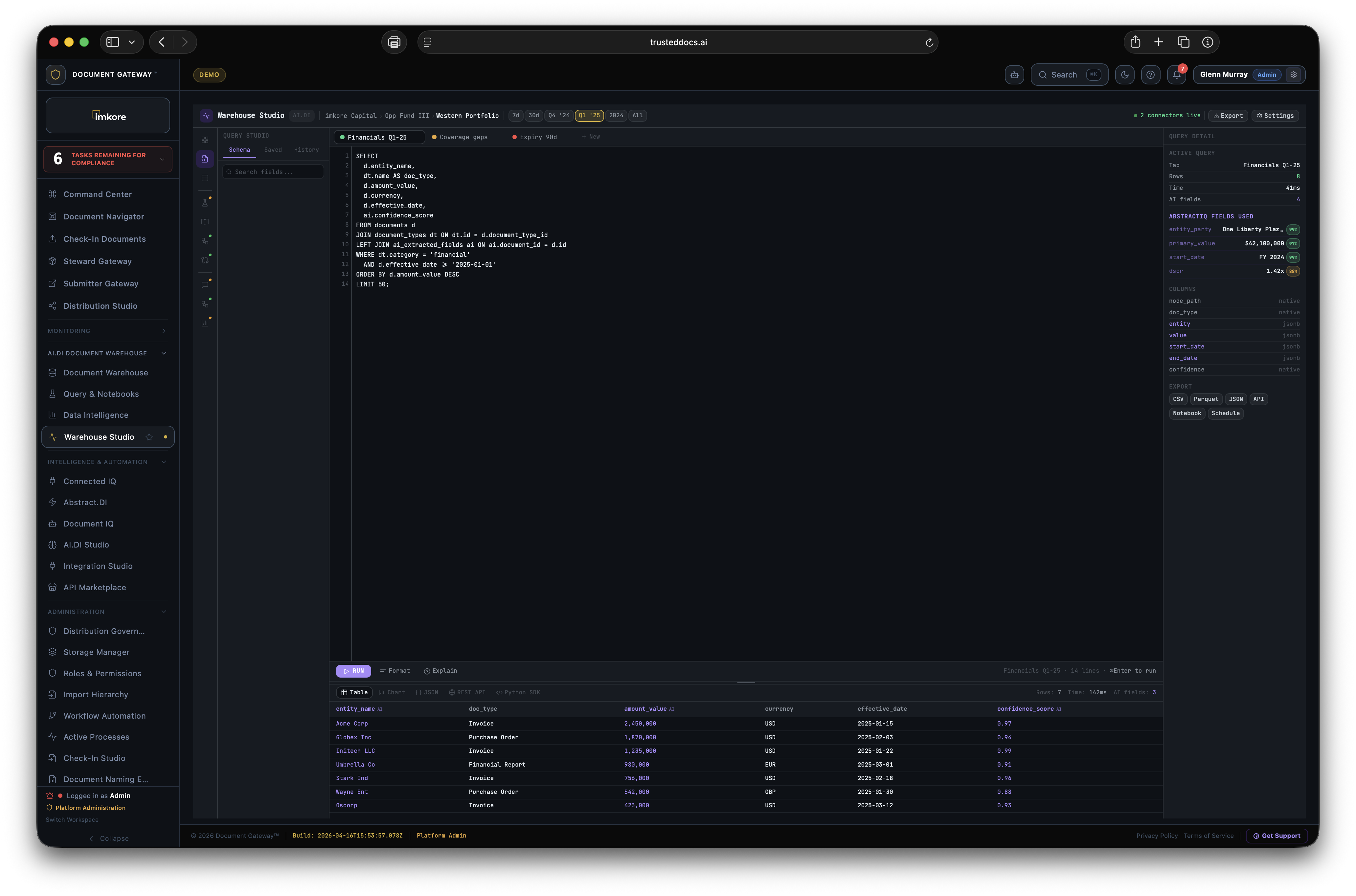
mv_document_universe materialized view provides a single queryable source across all document types and extraction fields simultaneously.document.ingested, document.extracted, anomaly.detected, compliance.updated, sync.completed. Retry logic with exponential backoff. Used for ERP integration and downstream automation.pip install document-gateway. Pandas-native output — client.query("SELECT * FROM documents") returns a DataFrame directly. Async support. Used in notebooks, data science workflows, and custom analysis scripts.mv_document_universe), Query Engine (PostgREST plus custom SQL).Every other platform in the document space stores files. AI.DI stores intelligence. The gap between those two sentences is what makes AI.DI indispensable the longer you use it. A corpus of ten thousand documents with eighteen months of extraction history, anomaly signals, steward corrections, and financial time series data is not a folder of files anymore. It is your most strategic data asset. The deeper that asset goes, the harder it is to imagine running the organization without it.
Effortlessly capture and ensure accurate classification from any application. FileStar centralizes all document types, paper or electronic, into a unified system with required fields and built in approval workflows that guarantee consistent, accurate archiving.
FileStar enforces stringent controls and compliance with precision and accountability at every step. Complex workflows can be modeled to exact requirements with sequential and parallel routing, escalation paths, and automated notifications.
Protect your critical documents in a centralized repository with security and compliance built in from the foundation. The Archive is the governed system of record. Every version, every action, every access event is logged and preserved.
A document schema is the structured framework that defines how documents are identified, categorized, and related to one another. Just as a data warehouse relies on a data schema to bring order to large volumes of information, a document warehouse uses a document schema to create clarity, consistency, and predictable organization across all documents.
FileStar's schema spans more than 5,700 unique document types — giving it deep understanding of documents that support acquisitions, operations, financings, compliance, and every stage of the enterprise lifecycle. The schema automatically knows what a document is, how it should be classified, where it belongs, and what a complete document chain should look like. Documents are no longer scattered or mislabeled — they are organized consistently across systems and ready for audit, operations, and enterprise-wide decision making.
Metadata is to documents what structured fields are to data. FileStar identifies and extracts key attributes (document type, parties, dates, asset identifiers, and relationships) transforming unstructured files into structured intelligence. Without metadata, documents behave like raw data with no schema. With metadata, they become organized, trustworthy knowledge assets that support search, governance, compliance, and AI.
Every document in FileStar is a governed asset aligned with a consistent taxonomy and storage structure — searchable through clear logical pathways by type, entity, process, source system, date, or business function. Dynamic views and dashboards give teams visibility into entire document collections, not just isolated files.
Auditability is a defining characteristic of a document warehouse. FileStar records every interaction with every document and preserves the full lineage of a record from its originating system through every update and review. Auditors can see exactly where a document came from, how it has been handled, and whether it remains complete and accurate.
FileStar also captures the source system, timestamps, authorship, and movement of each document — creating a verified chain of custody. This transparency builds trust across the organization and satisfies regulatory requirements without additional documentation work.
FileStar operates within an SSAE 18 certified hosting facility with annual SOC II audits. Role-based access controls ensure only authorized users and groups can access specific documents. All protocols comply with HIPAA and SOX guidelines for PII and PHI.
Compliance becomes easier when documents follow a consistent structure and lifecycle. FileStar enforces rules for document retention, validation, storage, and access — providing real time visibility into document completeness, timeliness, and accuracy. This makes it simpler to prove adherence to regulations and internal policies, and reduces the risk associated with missing or misplaced documents.
FileStar governs documents. AI.DI makes them intelligent. FileStar managed documents automatically flow through Sentry certification and Abstract.DI extraction without any workflow change for existing users. All FileStar metadata syncs to the AI.DI Warehouse continuously.
Every FileStar client is one conversation away from the full AI.DI platform. No rip and replace. No migration project. No change management crisis. The upgrade path is a configuration change — the governance infrastructure is already in place.
imkore Millennia was founded in 1996 with a focus on tailored document solutions for complex requirements that standard document management software cannot easily meet. The combination of SaaS flexibility with customizable framework design means FileStar can be configured for specific industries, regulatory environments, and workflow structures without professional services for standard deployments.
Every CIO has seen the same pattern. The organization signs a deal for an AI assistant. The pilot goes well. The rollout begins. And then the AI starts hallucinating. Wrong contract terms. Made up dates. Confident answers that are factually false. The model is not the problem. The data is. The AI was reasoning over a chaotic, uncertified, duplicated mess of documents and producing exactly the answers that input deserves. AI Orchestration was built to solve this permanently. Every AI agent in your organization gets a single, trusted, certified, structured Document Intelligence foundation to reason from. Every answer is traceable to a specific certified document. Every fact has provenance. Every query respects access control. AI deployments finally graduate from pilot to production.
Most AI vendors lock you into their model. We do not. Use Claude. Use Copilot. Use ChatGPT. Use Gemini. Use Grok. Use Llama. Use a model your team built. Use all of them at the same time. AI.DI is LLM agnostic by design. The published MCP server speaks Model Context Protocol for Claude, Cursor, and LangChain. The same endpoint serves REST and OpenAPI for ChatGPT GPT Actions and any HTTP capable agent framework. One endpoint. Two protocol surfaces. Every tool available on both. Your agents do not care which AI vendor your organization uses next.
Every MCP key is tenant scoped. Every tool call is authenticated. Every query respects PostgreSQL row level security policies enforced at the database. An agent cannot access documents the connecting user is not authorized to see. Keys are revocable in one click. Every action is logged with full provenance. AI deployments meet enterprise security and audit requirements out of the box.
The agent-gateway edge function receives all AI agent requests and dispatches them to the appropriate tool handlers. It enforces authentication, validates the requesting agent's access scope, applies row-level security policies, and logs every tool invocation for the audit trail.
Supports Bearer token authentication for API clients and session-based auth for browser-connected agents. Rate limiting per API key. Tool-level permission grants — a key can be scoped to read only document retrieval without access to warehouse queries or compliance data.
A single Supabase Deno edge function serving both the Model Context Protocol (SSE transport for Claude and Cursor) and a REST/OpenAPI interface (for ChatGPT GPT Actions, LangChain, AutoGen, and any HTTP agent).
The same tool definitions, the same security model, the same data — two protocol surfaces from one deployment. ChatGPT integration operational. Deployed with --no-verify-jwt to support custom Bearer token auth independent of Supabase session auth.
Receives inbound webhook events from enterprise ERPs, CRM platforms, and any connected system. Validates payload signatures, routes events to the appropriate pipeline stage, and triggers document processing or metadata updates without human involvement.
When a contract is executed in an ERP, the erp-webhook fires the checkin-pipeline automatically — the document enters the AI extraction queue without anyone touching Document Gateway directly.
Cron-triggered orchestration functions that run batch operations on a configurable schedule. Batch pipeline runs process large document queues during off-peak hours. Scheduled reports generate and distribute compliance summaries, expiry alerts, and portfolio intelligence reports automatically.
No human trigger required for ongoing operations. The platform monitors itself, processes new documents, updates CTR scores, and delivers reports on schedule — continuously.
Access control is not application layer middleware. Every Supabase table has PostgreSQL row level security policies that enforce which rows a given user can read, write, or delete, based on their role, their organization, and their specific entity permissions.
An AI agent authenticating with an API key receives exactly the same data access as the human user who created that key — not more, not less. Even if the agent constructs a warehouse query attempting to access data outside its scope, PostgreSQL silently returns only authorized rows. The restriction is invisible to the caller and unbypassable by any query construction.
Every API key is scoped to a specific user, organization, and permission set at creation time. Keys can be restricted to specific tools, specific entities, or read only operations.
Every enterprise deploying Copilot, GPT-4, Claude, or Gemini on their documents faces the same problem: the AI is only as good as the data it reasons from. Uncertified documents produce hallucinated answers. Unstructured files produce generic summaries. AI.DI is the certified, structured document foundation that transforms any LLM from a document summarizer into a reliable enterprise intelligence system.
AI.DI gives your organization Continuous Transaction Readiness — the state where every document across every system is accessible, authentic, current, and actionable at all times. Organizations that achieve this state lower their cost of capital, reduce audit risk, accelerate transactions, deploy AI with confidence, and eliminate the document scramble that precedes every critical business event.
Every document management platform ever built (M-Files, Hyland, Box, SharePoint, Laserfiche, OpenText) operates on the same passive model. A human asks a question. The system returns a file. The documents do not know they are incomplete. The system does not know a transaction is approaching. No one is told what is missing until the moment it actually matters.
CTR inverts this model. The platform continuously monitors the entire document estate against a dynamic requirement model, scores readiness in real time, and surfaces gaps before they become crises. The difference between reactive retrieval and proactive readiness is the difference between document management and document intelligence.
To calculate a CTR score, you need to know: which documents are required, which are present, which are valid, which are current, which have changed, and which are expired. A file storage system knows none of this. It knows filenames and folder paths.
AI.DI knows all of this because Abstract.DI has read every document, Sentry has fingerprinted and certified every document, and the Warehouse stores every extracted field — including expiry dates, version identifiers, compliance flags, and obligation terms — as queryable structured data. CTR is computed from that data continuously. No competitor has that data. None can build it without starting over.
Every organization faces recurring high stakes document events. Regulatory audits. Financing processes. M&A due diligence. Partner onboarding. Contract renewals. Compliance filings. Board reviews. In every case the weeks before the event are consumed by the same document scramble. Finding files. Verifying versions. Hunting for missing certificates. Correcting outdated records.
CTR eliminates that scramble permanently. The organization is ready before the event is announced. That is not an incremental improvement. It is a fundamentally different value proposition — one that no existing platform can match because none of them understand what their documents say.
| Score | Status | Typical Situation | Time to Transact |
|---|---|---|---|
| 90–100 | Transaction Ready | All documents present, current, and certified. No violations. Counterparty package deployable in hours. | 48 hours |
| 75–89 | Near Ready | 1–3 documents missing or expiring. No active violations. Gaps identified and assigned. | 1–5 business days |
| 55–74 | Attention Required | Multiple gaps or 1–2 violations. Transaction possible but counterparty will surface issues. | 2–4 weeks |
| 35–54 | Not Ready | Significant document gaps. Will not survive regulatory or counterparty diligence in current state. | 30–60 days |
| 0–34 | Critical | Severely incomplete or noncompliant. Immediate remediation required across multiple dimensions. | 90+ days |
| Capability | M-Files / Hyland / OpenText | Box / SharePoint | AI.DI |
|---|---|---|---|
| Real time readiness score | None | None | CTR Score — continuous |
| Automatic gap detection | Manual checklist | None | Continuous AI monitoring |
| Document content intelligence | Metadata tags only | None | Full field extraction |
| Expiry and validity tracking | Manual with reminders | None | Automated from extracted dates |
| Counterparty package readiness | Manual assembly | Manual assembly | Pre-assembled, certified |
| Compliance posture visibility | Periodic reports | None | Continuous, real time |
| AI-ready data foundation | Raw files only | Raw files only | Certified structured data |
| Version certification | Version numbers only | Version numbers only | Sentry fingerprint certified |
AI.DI is not a document management UI with an API bolted on. It is a document intelligence data platform: a PostgreSQL warehouse of structured document intelligence, a MCP server, a webhook event stream, a REST/GraphQL API, Snowflake Data Share, JDBC/ODBC direct access, vector embeddings on certified document chunks, and a 30-engine ML pipeline that improves continuously. Every document becomes structured, provenance tracked, certified data — available to any model, pipeline, or analytics tool you're running.
| Table | Contents | Key Fields | Primary Use |
|---|---|---|---|
document_records | Every document processed | id, original_name, document_type, workflow_status, asset_id, classification_confidence, storage_path | Document inventory, classification analysis |
extracted_fields | Structured extraction from Abstract.DI | document_id, field_name, field_value, confidence_score, extraction_model, extraction_timestamp | Contract analytics, financial extraction |
sentry_fingerprints | Cryptographic fingerprint records | document_id, fingerprint_hash, fingerprint_type, certified_at, version_chain, similarity_scores | Certification, duplicate detection, fraud monitoring |
hierarchy_nodes | Full org hierarchy | id, parent_id, node_type, node_name, industry, ctr_score, completeness_pct | Portfolio analytics, CTR aggregation |
document_activity_log | Every action on every document | document_id, event_type, actor_id, actor_role, timestamp, metadata | Audit trail, access pattern analysis |
vector_embeddings | Embeddings on certified chunks | document_id, chunk_id, certified_version_hash, embedding_vector, model_version | Semantic search, RAG retrieval, clustering |
ctr_score_history | CTR Score time series | node_id, score, dimension_scores, calculated_at, delta_from_prior | Readiness trending, portfolio benchmarking |
| Department | Acute Pain | AI.DI Entry Product | Expansion Path |
|---|---|---|---|
| Legal / GC | Contract version disputes, discovery liability, GDPR compliance | Sentry certification + Document Gateway distribution | Full Document Warehouse for corporate legal corpus |
| Finance / Accounting | Audit prep fire drills, financial document reconciliation | Abstract.DI batch (financial extraction) + Blueprint audit | Sentry certification + Warehouse integration to ERP |
| Compliance / Risk | Regulatory filing tracking, compliance gaps, audit exposure | Sentry + Warehouse (compliance corpus) + CTR Score | Full platform across regulated document types |
| Transactions / Deal Team | Due diligence prep time, data room chaos | Document Gateway + Distribution Studio + Transaction Rooms | Abstract.DI batch for portfolio wide extraction |
| IT / Data Engineering | Unstructured data not in Snowflake; LLM hallucinations | Document Warehouse + Snowflake + MCP Server | Full platform as enterprise document intelligence backbone |
| Operations / HR | Employee records, policy tracking, onboarding compliance | FileStar lifecycle governance + Abstract.DI HR extraction | Sentry certification + Document Gateway policy distribution |
The world's largest institutional real estate portfolios run on the same platform as a 12-asset regional operator starting their first compliance program. A single compliance officer in one department gets the same AI intelligence, the same CTR Score, the same Warehouse, the same MCP server as a 500-person investment management firm running 20 funds. We built for scale from day one — which means the smallest client gets the most powerful platform available at any price point. No feature tiers. No locked capabilities. No "upgrade to get the real thing."
Blueprint evaluates your entire document ecosystem (every repository, every system, every process) and delivers a scored readiness assessment plus a prioritized AI.DI product roadmap. Blueprint always reveals exactly which products you need and why. The roadmap we deliver is the AI.DI implementation plan for your organization.
You get the full framework. You only pay for what you use. Every customer gets the entire AI.DI platform on day one. Every engine. Every studio. Every integration. The only thing you ever pay for is the AI consumption your organization actually generates.
You get the full platform the moment you deploy. Every engine. Every view. Every integration. There are no feature gates, no capability tiers, and no "enterprise unlock" for core functionality. Your first document gets the same AI pipeline as document number one million. You see the full value of the framework immediately. You do not earn access to it through a ramp up process.
No. AI.DI layers over your existing infrastructure. Start with your highest priority document program or begin fresh with new documents. There is no requirement to migrate your entire historical archive before going live. The batch engine processes any legacy archive on its own timeline. You decide when and what to bring in.
Sentry generates a mathematical fingerprint, which is a unique hash derived from document content. Two identical documents always produce identical fingerprints. Any change produces a different fingerprint. The original document is never stored by Sentry. GDPR data minimization is achieved structurally. Your documents never leave your control.
The MCP server exposes six tools. search_documents. get_compliance_status. get_obligations. query_warehouse. get_hierarchy. get_document_url. Plug AI.DI into Claude, Cursor, LangChain, AutoGen, or any MCP compatible environment and your agents instantly gain certified document search and structured extraction queries. Authentication runs through OAuth2. Agents only access what the connecting user is authorized to see. Keys are revocable in one click.
Yes. The full platform deploys through Docker containers. No Kubernetes required. Azure, AWS, fully on premise, and hybrid (metadata in cloud, documents on premise) are all supported. Air gapped environments with no internet connectivity are also supported. Contact the enterprise team for deployment architecture details.
Snowflake Data Share (zero copy, no ETL). Databricks connector (Delta Lake, streaming). Tableau and Power BI native connectors. dbt compatibility. BigQuery export. Direct JDBC and ODBC access. REST API with full OpenAPI 3.0 spec. Python SDK. Webhook event streaming to any HTTP endpoint. SSO through SAML 2.0 and OAuth 2.0.